机器学习实践
一:海量文件遍历
工作目录:

!tree -L 3 ./data/
./data/
└── data10954
├── cat_12_test.zip
├── cat_12_train.zip
└── train_list.txt
#显示文件目录详情
import zipfile
import os
def unzip_data(src_path,target_path):
# 解压原始数据集,将src_path路径下的zip包解压至target_path目录下
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
unzip_data('data/data10954/cat_12_train.zip','data/data10954/cat_12_train')
unzip_data('data/data10954/cat_12_test.zip','data/data10954/cat_12_test')
#解压文件
import os
"""
通过给定目录,统计所有的不同子文件类型及占用内存
"""
size_dict = {}
type_dict = {}
def get_size_type(path):
files = os.listdir(path)
for filename in files:
temp_path = os.path.join(path, filename)
if os.path.isdir(temp_path):
# 递归调用函数,实现深度文件名解析
get_size_type(temp_path)
elif os.path.isfile(temp_path):
# 获取文件后缀
type_name=os.path.splitext(temp_path)[1]
#无后缀名的文件
if not type_name:
type_dict.setdefault("None", 0)
type_dict["None"] += 1
size_dict.setdefault("None", 0)
size_dict["None"] += os.path.getsize(temp_path)
# 有后缀的文件
else:
type_dict.setdefault(type_name, 0)
type_dict[type_name] += 1
size_dict.setdefault(type_name, 0)
# 获取文件大小
size_dict[type_name] += os.path.getsize(temp_path)
path= "data/"
get_size_type(path)
for each_type in type_dict.keys():
print ("%5s下共有【%5s】的文件【%5d】个,占用内存【%7.2f】MB" %
(path,each_type,type_dict[each_type],\
size_dict[each_type]/(1024*1024)))
print("总文件数: 【%d】"%(sum(type_dict.values())))
print("总内存大小:【%.2f】GB"%(sum(size_dict.values())/(1024**3)))二:简单计算器实现
抽象出几个函数:
(1)弹栈时计算‘两个数字和运算符组成的算式’结果的函数。
(2)判断元素是数字还是运算符的函数。
(3)把算式处理成列表形式的函数。如:’-1-2*((-2+3)+(-2/2))’ 应该处理成:[‘-1’, ‘-‘, ‘2’, ‘*’, ‘(‘, ‘(‘, ‘-2’, ‘+’, ‘3’, ‘)’, ‘+’, ‘(‘, ‘-2’, ‘/‘, ‘2’, ‘)’, ‘)’] 。
(4)决策函数,决定应该是入栈,弹栈运算,还是弹栈丢弃。
(5)主函数,遍历算式列表,计算最终结果。
import re
def calculate(n1, n2, operator):
'''
:param n1: float
:param n2: float
:param operator: + - * /
:return: float
'''
result = 0
if operator == "+":
result = n1 + n2
if operator == "-":
result = n1 - n2
if operator == "*":
result = n1 * n2
if operator == "/":
result = n1 / n2
return resultdef calculate(n1, n2, operator):
'''
:param n1: float
:param n2: float
:param operator: + - * /
:return: float
'''
result = 0
if operator == "+":
result = n1 + n2
if operator == "-":
result = n1 - n2
if operator == "*":
result = n1 * n2
if operator == "/":
result = n1 / n2
return result
# 判断是否是运算符,如果是返回True
def is_operator(e):
'''
:param e: str
:return: bool
'''
opers = ['+', '-', '*', '/', '(', ')']
return True if e in opers else False
# 将算式处理成列表,解决-是负数还是减号
def formula_format(formula):
# 去掉算式中的空格
formula = re.sub(' ', '', formula)
# 以 '横杠数字' 分割, 其中正则表达式:(\-\d+\.?\d*) 括号内:
# \- 表示匹配横杠开头; \d+ 表示匹配数字1次或多次;\.?表示匹配小数点0次或1次;\d*表示匹配数字1次或多次。
formula_list = [i for i in re.split('(\-\d+\.?\d*)', formula) if i]
# 最终的算式列表
final_formula = []
for item in formula_list:
# 第一个是以横杠开头的数字(包括小数)final_formula。即第一个是负数,横杠就不是减号
if len(final_formula) == 0 and re.search('^\-\d+\.?\d*$', item):
final_formula.append(item)
continue
if len(final_formula) > 0:
# 如果final_formal最后一个元素是运算符['+', '-', '*', '/', '('], 则横杠数字不是负数
if re.search('[\+\-\*\/\(]$', final_formula[-1]):
final_formula.append(item)
continue
# 按照运算符分割开
item_split = [i for i in re.split('([\+\-\*\/\(\)])', item) if i]
final_formula += item_split
return final_formula
def decision(tail_op, now_op):
'''
:param tail_op: 运算符栈的最后一个运算符
:param now_op: 从算式列表取出的当前运算符
:return: 1 代表弹栈运算,0 代表弹运算符栈最后一个元素, -1 表示入栈
'''
# 定义4种运算符级别
rate1 = ['+', '-']
rate2 = ['*', '/']
rate3 = ['(']
rate4 = [')']
if tail_op in rate1:
if now_op in rate2 or now_op in rate3:
# 说明连续两个运算优先级不一样,需要入栈
return -1
else:
return 1
elif tail_op in rate2:
if now_op in rate3:
return -1
else:
return 1
elif tail_op in rate3:
if now_op in rate4:
return 0 # ( 遇上 ) 需要弹出 (,丢掉 )
else:
return -1 # 只要栈顶元素为(,当前元素不是)都应入栈。
else:
return -1
def final_calc(formula_list):
num_stack = [] # 数字栈
op_stack = [] # 运算符栈
for e in formula_list:
operator = is_operator(e)
if not operator:
# 压入数字栈
# 字符串转换为符点数
num_stack.append(float(e))
else:
# 如果是运算符
while True:
# 如果运算符栈等于0无条件入栈
if len(op_stack) == 0:
op_stack.append(e)
break
# decision 函数做决策
tag = decision(op_stack[-1], e)
if tag == -1:
# 如果是-1压入运算符栈进入下一次循环
op_stack.append(e)
break
elif tag == 0:
# 如果是0弹出运算符栈内最后一个(, 丢掉当前),进入下一次循环
op_stack.pop()
break
elif tag == 1:
# 如果是1弹出运算符栈内最后两个元素,弹出数字栈最后两位元素。
op = op_stack.pop()
num2 = num_stack.pop()
num1 = num_stack.pop()
# 执行计算
# 计算之后压入数字栈
num_stack.append(calculate(num1, num2, op))
# 处理大循环结束后 数字栈和运算符栈中可能还有元素 的情况
while len(op_stack) != 0:
op = op_stack.pop()
num2 = num_stack.pop()
num1 = num_stack.pop()
num_stack.append(calculate(num1, num2, op))
return num_stack, op_stack
if __name__ == '__main__':
formula = input('请输入:\n')
# formula = "1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2))"
print("算式:", formula)
formula_list = formula_format(formula)
result, _ = final_calc(formula_list)
print("计算结果:", result[0])三:数据直方图统计分析
#准备数据集
!mkdir /home/aistudio/external-libraries
!pip install beautifulsoup4 -t /home/aistudio/external-libraries
灰度直方图概括了图像的灰度级信息,简单的来说就是每个灰度级图像中的像素个数以及占有率,创建直方图无外乎两个步骤,统计直方图数据,再用绘图库绘制直方图。
统计直方图数据 首先要稍微理解一些与函数相关的术语,方便理解其在python3库中的应用和处理 BINS: 在上面的直方图当中,如果像素值是0到255,则需要256个值来显示直 方图。但是,如果不需要知道每个像素值的像素数目,只想知道两个像素值之间的像素点数目怎么办?例如,想知道像素值在0到15之间的像素点数目,然后是16到31。。。240到255。可以将256个值分成16份,每份计算综合。每个分成的小组就是一个BIN(箱)。在opencv中使用histSize表示BINS。 DIMS: 数据的参数数目。当前例子当中,对收集到的数据只考虑灰度值,所以该值为1。 RANGE: 灰度值范围,通常是[0,256],也就是灰度所有的取值范围。 统计直方图同样有两种方法,使用opencv统计直方图,函数如下:
cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
#利用hist直接绘制图像
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('nezha.jpg',1)
print(img)
# img_np = np.array(img)
plt.hist(img.reshape([-1]),256,[0,256]);
#这里因为像素点都是0~255,所以这里的bin选择是256
plt.show()
cv2.calcHist([images], [channels], mask, histSize, ranges[, hist[, accumulate ]])
imaes:输入的图像
channels:选择图像的通道
mask:掩膜,是一个大小和image一样的np数组,其中把需要处理的部分指定为1,不需要处理的部分指定为0,一般设置为None,表示处理整幅图像
histSize:使用多少个bin(柱子),一般为256
ranges:像素值的范围,一般为[0,255]表示0~255
#显示灰色通道,只有一个通道
import cv2
# import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('nezha.jpg',0)
histr = cv2.calcHist([img],[0],None,[256],[0,256]) #hist是一个shape为(256,1)的数组,表示0-255每个像素值对应的像素个数,下标即为相应的像素值
plt.plot(histr,color = 'b')
plt.xlim([0,256])
plt.show()
#显示三色通道,每一个通道展示像素点
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('nezha.jpg',1)
color = ('b','g','r')
for i,col in enumerate(color):
histr = cv2.calcHist([img],[i],None,[256],[0,256])
#hist是一个shape为(256,1)的数组,表示0-255每个像素值对应的像素个数,下标即为相应的像素值
plt.plot(histr,color = col)
plt.xlim([0,256])
plt.show()
import sys
import numpy as np
import cv2
import matplotlib.pyplot as plt
def main():
img=cv2.imread('nezha.jpg',0)
print(img.shape)
#得到计算灰度直方图的值
n = np.array(img)
print(n.shape)
xy=xygray(img)
#画出灰度直方图
x_range=range(256)
plt.plot(x_range,xy,"r",linewidth=2)
#设置坐标轴的范围
y_maxValue=np.max(xy)
plt.axis([0,255,0,y_maxValue])
#设置坐标轴的标签
plt.xlabel('gray Level')
plt.ylabel("number of pixels")
plt.show()
def xygray(img):
#得到高和宽
rows,cols=img.shape
print(img.shape)
#存储灰度直方图
xy=np.zeros([256],np.uint64)
print(xy.shape)
for r in range(rows):
for c in range(cols):
xy[img[r][c]] += 1
#返回一维ndarry
print(xy.sum())
return xy
main()四:文本词频分析
import jieba # jieba中文分词库
with open('data/data131368/test.txt', 'r', encoding='UTF-8') as novelFile:
novel = novelFile.read()
# print(novel)
stopwords = [line.strip() for line in open('data/data131368/stop.txt', 'r', encoding='UTF-8').readlines()]
print(stopwords)
novelList = list(jieba.lcut(novel))
print(novelList)
novelDict = {}
# 统计出词频字典
for word in novelList:
if word not in stopwords:
# 不统计字数为一的词
if len(word) == 1:
continue
else:
novelDict[word] = novelDict.get(word, 0) + 1
# 对词频进行排序
novelListSorted = list(novelDict.items())
novelListSorted.sort(key=lambda e: e[1], reverse=True)
#另外的排序方式
#ClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
# 打印前10词频
topWordNum = 0
for topWordTup in novelListSorted[:10]:
print(topWordTup)
from matplotlib import pyplot as plt
x = [c for c,v in novelListSorted]
y = [v for c,v in novelListSorted]
plt.plot(x[:10],y[:10],color='r')
plt.show()
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
from imageio import imread
#读入背景图片
from main import novelDict
bg_pic = imread('父亲.jpg')
#生成词云图片
wordcloud = WordCloud(mask=bg_pic,background_color='black',\
scale=1.5,font_path=r'data\msyh.ttc').generate(' '.join(novelDict.keys()))
plt.imshow(wordcloud) #显示生成的词云图
plt.axis('off') #关闭坐标轴显示
plt.show()
#保存图片
wordcloud.to_file('父亲2.jpg')五:图片爬取
refer和url不冲突吗
在HTTP请求中,Referer(引用页)是指当前请求的来源页面的URL。当你在浏览器中点击链接或提交表单时,浏览器会发送HTTP请求,并在请求头中包含Referer字段,指示该请求是从哪个页面链接过来的。
在给定的代码中,`self.headers_image`中的Referer字段用于指定请求的来源页面,即告诉服务器该请求是从百度图片搜索页面链接过来的。这可以用于一些网站的访问控制或统计分析。
在下载图片的部分,`f.write(requests.get(url, headers=self.headers_image).content)`中的headers参数被用来传递请求头信息,其中包括Referer字段。这样做是为了模拟浏览器行为,使服务器认为请求是从百度图片搜索页面来的,以提高请求的成功率。
虽然URL已经包含了目标图片的地址,但有些网站可能会检查Referer字段以防止直接链接到图片资源。因此,在下载图片时使用正确的Referer可以增加请求的成功率。
需要注意的是,不是所有网站都对Referer进行验证,有些网站可能会忽略或不使用Referer字段。因此,根据实际情况,你可以选择在请求中包含或省略Referer字段。import requests
import os
import urllib
class GetImage():
def __init__(self,keyword='大雁',paginator=1):
# self.url: 链接头
self.url = 'http://image.baidu.com/search/acjson?' #百度图片网站
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT\
10.0; Win64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36'}
self.headers_image = {
'User-Agent': 'Mozilla/5.0 (Windows\
NT 10.0; WOW64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36',
'Referer': 'http://image.baidu.com/\
search/index?tn=baiduimage&ipn=r&\
ct=201326592&cl=2&lm=-1&st=-1&\
fm=result&fr=&sf=1&fmq=1557124645631_R&\
pv=&ic=&nc=1&z=&hd=1&latest=0©right\
=0&se=1&showtab=0&fb=0&width=&height=\
&face=0&istype=2&ie=utf-8&sid=&word=%\
E8%83%A1%E6%AD%8C'}
self.keyword = keyword # 定义关键词
self.paginator = paginator # 定义要爬取的页数
def get_param(self):
# 将中文关键词转换为符合规则的编码
keyword = urllib.parse.quote(self.keyword)
params = []
# 为爬取的每页链接定制参数
for i in range(1, self.paginator + 1):
params.append(
'tn=resultjson_com&ipn=rj&ct=201326592&is=&\
fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&o\
e=utf-8&adpicid=&st=-1&z=&ic=&hd=1&latest=0&\
copyright=0&word={}&s=&se=&tab=&width=&height\
=&face=0&istype=2&qc=&nc=1&fr=&expermode=&for\
ce=&cg=star&pn={}&rn=30&gsm=78&1557125391211\
='.format(keyword, keyword, 30 * i))
return params # 返回链接参数
def get_urls(self, params):
urls = []
for param in params:
# 拼接每页的链接
urls.append(self.url + param)
return urls # 返回每页链接
def get_image_url(self, urls):
image_url = []
print(len(urls))
for url in urls:
json_data = requests.get(url, headers=self.headers).json()
print(json_data)
json_data = json_data.get('data')
print(json_data)
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
def get_image(self, image_url):
"""
根据图片url,在本地目录下新建一个以搜索关键字命名的文件夹,然后将每一个图片存入。
:param image_url:
:return:
"""
cwd = os.getcwd()
file_name = os.path.join(cwd, self.keyword)
if not os.path.exists(self.keyword):
os.mkdir(file_name)
for index, url in enumerate(image_url, start=1):
print(f"下载的url是{url}")
with open(file_name+'/{}_0.jpg'.format(index), 'wb') as f:
f.write(requests.get(url, headers=self.headers_image).content)
if index != 0 and index % 30 == 0:
print('第{}页下载完成'.format(index/30))
def __call__(self, *args, **kwargs):
params = self.get_param() # 获取链接参数
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
print(len(image_url))
self.get_image(image_url)
if __name__ == '__main__':
spider = GetImage('明星图片', 3)
spider()
# spider = GetImage('雕', 3)
# spider()六:股票行情爬取与分析
!pip install fake_useragent
!pip install bs4
!cp /home/aistudio/simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
!cp /home/aistudio/simhei.ttf .fonts/
!rm -rf .cache/matplotlib
#coding=utf-8
'''
Created on 2021年02月20日
@author: zhongshan
'''
#http://quote.eastmoney.com/center/gridlist.html
#爬取该页面股票信息
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import json
import csv
def getHtml(url):
r = requests.get(url,headers={
'User-Agent': UserAgent().random,
})
r.encoding = r.apparent_encoding
return r.text
#num为爬取多少条记录,可手动设置
num = 20
#该地址为页面实际获取数据的接口地址
stockUrl='http://99.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408733409809437476_1623137764048&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1623137764167:formatted'
if __name__ == '__main__':
responseText = getHtml(stockUrl)
jsonText = responseText.split("(")[1].split(")")[0];
resJson = json.loads(jsonText)
datas = resJson["data"]["diff"]
datalist = []
for data in datas:
# if (str().startswith('6') or str(data["f12"]).startswith('3') or str(data["f12"]).startswith('0')):
row = [data["f12"],data["f14"]]
datalist.append(row)
print(datalist)
f =open('stock.csv','w+',encoding='utf-8',newline="")
writer = csv.writer(f)
writer.writerow(('代码', '名称'))
for data in datalist:
writer.writerow((data[0]+"\t",data[1]+"\t"))
f.close()
七:科比职业生涯数据爬取与分析
# coding=utf-8
'''
Created on 2021年02月20日
@author: zhongshan
'''
import requests
from bs4 import BeautifulSoup
import csv
import matplotlib.pyplot as plt
import pandas as pd
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['simhei'] # 指定默认字体
# plt.rcParams['font.sans-serif']=['Fangsong'] # 用来显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来显示负号
plt.rcParams['figure.dpi'] = 100 # 每英寸点数
def getKobeList(code):
url = "http://www.stat-nba.com/player/stat_box/195_" + code + ".html"
response = requests.get(url)
resKobe = response.text
return resKobe
# 获取kobe历史数据
def getRow(resKobe, code):
soup = BeautifulSoup(resKobe, "html.parser")
table = soup.find_all(id='stat_box_avg')
# 表头
header = []
if code == "season":
header = ["赛季", "出场", "首发", "时间", "投篮", "命中", "出手", "三分", "命中", "出手", "罚球", "命中",
"出手", "篮板", "前场", "后场", "助攻", "抢断", "盖帽", "失误", "犯规", "得分", "胜", "负"]
if code == "playoff":
header = ["赛季", "出场", "时间", "投篮", "命中", "出手", "三分", "命中", "出手", "罚球", "命中", "出手",
"篮板", "前场", "后场", "助攻", "抢断", "盖帽", "失误", "犯规", "得分", "胜", "负"]
if code == "allstar":
header = ["赛季", "首发", "时间", "投篮", "命中", "出手", "三分", "命中", "出手", "罚球", "命中", "出手",
"篮板", "前场", "后场", "助攻", "抢断", "盖帽", "失误", "犯规", "得分"]
# 数据
rows = [];
rows.append(header)
for tr in table[0].find_all("tr", class_="sort"):
row = []
for td in tr.find_all("td"):
rank = td.get("rank")
if rank != "LAL" and rank != None:
row.append(td.get_text())
rows.append(row)
return rows
# 写入csv文件,rows为数据,dir为写入文件路径
def writeCsv(rows, dir):
with open(dir, 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
writer.writerows(rows)
# 常规赛数据
resKobe = getKobeList("season")
rows = getRow(resKobe, "season")
# print(rows)
writeCsv(rows, "season.csv")
print("season.csv saved")
# 季后赛数据
resKobe = getKobeList("playoff")
rows = getRow(resKobe, "playoff")
# print(rows)
writeCsv(rows, "playoff.csv")
print("playoff.csv saved")
# 全明星数据
resKobe = getKobeList("allstar")
rows = getRow(resKobe, "allstar")
# print(rows)
writeCsv(rows, "star.csv")
print("star.csv saved")
# 篮板、助攻、得分
def show_score(game_name='season', item='篮板', plot_name='line'):
# game_name: season, playoff, star
# item: 篮板,助攻,得分
# plot_name: line,bar
file_name = game_name + '.csv'
data = pd.read_csv(file_name)
X = data['赛季'].values.tolist()
X.reverse()
if item == 'all':
Y1 = data['篮板'].values.tolist()
Y2 = data['助攻'].values.tolist()
Y3 = data['得分'].values.tolist()
Y1.reverse()
Y2.reverse()
Y3.reverse()
else:
Y = data[item].values.tolist()
Y.reverse()
if plot_name == 'line':
if item == 'all':
plt.plot(X, Y1, c='r', linestyle="-.")
plt.plot(X, Y2, c='g', linestyle="--")
plt.plot(X, Y3, c='b', linestyle="-")
legend = ['篮板', '助攻', '得分']
else:
plt.plot(X, Y, c='g', linestyle="-")
legend = [item]
elif plot_name == 'bar':
# facecolor:表面的颜色;edgecolor:边框的颜色
if item == 'all':
fig = plt.figure(figsize=(15, 5))
ax1 = plt.subplot(131)
plt.bar(X, Y1, facecolor='#9999ff', edgecolor='white')
plt.legend(['篮板'])
plt.title('Kobe职业生涯数据分析:' + game_name)
plt.xticks(rotation=60)
plt.ylabel('篮板')
ax2 = plt.subplot(132)
plt.bar(X, Y2, facecolor='#999900', edgecolor='white')
plt.legend(['助攻'])
plt.title('Kobe职业生涯数据分析:' + game_name)
plt.xticks(rotation=60)
plt.ylabel('助攻')
ax3 = plt.subplot(133)
plt.bar(X, Y3, facecolor='#9988ff', edgecolor='white')
legend = ['得分']
else:
plt.bar(X, Y, facecolor='#9900ff', edgecolor='white')
legend = [item]
else:
return
plt.legend(legend)
plt.title('Kobe职业生涯数据分析:' + game_name)
plt.xticks(rotation=60)
plt.xlabel('赛季')
if item != 'all':
plt.ylabel(item)
else:
plt.ylabel('得分')
plt.savefig('Kobe职业生涯数据分析_{}_{}.png'.format(game_name, item))
plt.show()
# 篮板、助攻、得分
game_name = 'season'
for game_name in ['season', 'playoff', 'star']:
show_score(game_name=game_name, item='篮板', plot_name='bar')
show_score(game_name=game_name, item='助攻', plot_name='bar')
show_score(game_name=game_name, item='得分', plot_name='bar')
show_score(game_name=game_name, item='篮板', plot_name='line')
show_score(game_name=game_name, item='助攻', plot_name='line')
show_score(game_name=game_name, item='得分', plot_name='line')
show_score(game_name=game_name, item='all', plot_name='bar')
show_score(game_name=game_name, item='all', plot_name='line')
八:基于线性回归实现房价预测
经典的线性回归模型主要用来预测一些存在着线性关系的数据集。回归模型可以理解为:存在一个点集,用一条曲线去拟合它分布的过程。如果拟合曲线是一条直线,则称为线性回归。如果是一条二次曲线,则被称为二次回归。线性回归是回归模型中最简单的一种。 本教程使用PaddlePaddle建立起一个房价预测模型。
在线性回归中:
(1)假设函数是指,用数学的方法描述自变量和因变量之间的关系,它们之间可以是一个线性函数或非线性函数。 在本次线性回顾模型中,我们的假设函数为 Y’= wX+b ,其中,Y’表示模型的预测结果(预测房价),用来和真实的Y区分。模型要学习的参数即:w,b。
(2)损失函数是指,用数学的方法衡量假设函数预测结果与真实值之间的误差。这个差距越小预测越准确,而算法的任务就是使这个差距越来越小。 建立模型后,我们需要给模型一个优化目标,使得学到的参数能够让预测值Y’尽可能地接近真实值Y。这个实值通常用来反映模型误差的大小。不同问题场景下采用不同的损失函数。 对于线性模型来讲,最常用的损失函数就是均方误差(Mean Squared Error, MSE)。
(3)优化算法:神经网络的训练就是调整权重(参数)使得损失函数值尽可能得小,在训练过程中,将损失函数值逐渐收敛,得到一组使得神经网络拟合真实模型的权重(参数)。所以,优化算法的最终目标是找到损失函数的最小值。而这个寻找过程就是不断地微调变量w和b的值,一步一步地试出这个最小值。 常见的优化算法有随机梯度下降法(SGD)、Adam算法等等
import paddle
import numpy as np
import os
import matplotlib.pyplot as plt1.准备数据
(1)uci-housing数据集介绍
数据集共506行,每行14列。前13列用来描述房屋的各种信息,最后一列为该类房屋价格中位数。
(2)train_reader和test_reader(这个没看到懂)
paddle.reader.shuffle()表示每次缓存BUF_SIZE个数据项,并进行打乱
paddle.batch()表示每BATCH_SIZE组成一个batch
# BUF_SIZE=500
# BATCH_SIZE=20
# #用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
# train_reader = paddle.batch(
# paddle.reader.shuffle(paddle.dataset.uci_housing.train(),
# buf_size=BUF_SIZE),
# batch_size=BATCH_SIZE)
# #用于测试的数据提供器,每次从缓存中随机读取批次大小的数据
# test_reader = paddle.batch(
# paddle.reader.shuffle(paddle.dataset.uci_housing.test(),
# buf_size=BUF_SIZE),
# batch_size=BATCH_SIZE) 加载数据
#设置默认的全局dtype为float64
paddle.set_default_dtype("float64")
#下载数据
print('下载并加载训练数据')
train_dataset = paddle.text.datasets.UCIHousing(mode='train')
eval_dataset = paddle.text.datasets.UCIHousing(mode='test')
print(len(eval_dataset))
train_loader = paddle.io.DataLoader(train_dataset, batch_size=32, shuffle=True)
eval_loader = paddle.io.DataLoader(eval_dataset, batch_size = 8, shuffle=False)
print('加载完成')2.网络配置
对于线性回归来讲,它就是一个从输入到输出的简单的全连接层。
对于波士顿房价数据集,假设属性和房价之间的关系可以被属性间的线性组合描述。

# 定义全连接网络
class Regressor(paddle.nn.Layer):
def __init__(self):
super(Regressor, self).__init__()
# 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数
self.linear = paddle.nn.Linear(13, 1, None)
# 网络的前向计算函数
def forward(self, inputs):
x = self.linear(inputs)
return x
Batch=0
Batchs=[]
all_train_accs=[]
def draw_train_acc(Batchs, train_accs):
title="training accs"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("acc", fontsize=14)
plt.plot(Batchs, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
all_train_loss=[]
def draw_train_loss(Batchs, train_loss):
title="training loss"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(Batchs, train_loss, color='red', label='training loss')
plt.legend()
plt.grid()
plt.show()
model=Regressor() # 模型实例化
model.train() # 训练模式
mse_loss = paddle.nn.MSELoss()
opt=paddle.optimizer.SGD(learning_rate=0.0005, parameters=model.parameters())
epochs_num=200 #迭代次数
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_loader()):
image = data[0]
label = data[1]
predict=model(image) #数据传入model
# print(predict)
# print(np.argmax(predict,axis=1))
loss=mse_loss(predict,label)
# acc=paddle.metric.accuracy(predict,label.reshape([-1,1]))#计算精度
# acc = np.mean(label==np.argmax(predict,axis=1))
if batch_id!=0 and batch_id%10==0:
Batch = Batch+10
Batchs.append(Batch)
all_train_loss.append(loss.numpy()[0])
# all_train_accs.append(acc.numpy()[0])
print("epoch:{},step:{},train_loss:{}".format(pass_num,batch_id,loss.numpy()[0]) )
loss.backward()
opt.step()
opt.clear_grad() #opt.clear_grad()来重置梯度
paddle.save(model.state_dict(),'Regressor')#保存模型
draw_train_loss(Batchs,all_train_loss)
#模型评估
para_state_dict = paddle.load("Regressor")
model = Regressor()
model.set_state_dict(para_state_dict) #加载模型参数
model.eval() #验证模式
losses = []
infer_results=[]
groud_truths=[]
for batch_id,data in enumerate(eval_loader()):#测试集
image=data[0]
label=data[1]
groud_truths.extend(label.numpy())
predict=model(image)
infer_results.extend(predict.numpy())
loss=mse_loss(predict,label)
losses.append(loss.numpy()[0])
avg_loss = np.mean(losses)
print("当前模型在验证集上的损失值为:",avg_loss)
#绘制真实值和预测值对比图
def draw_infer_result(groud_truths,infer_results):
title='Boston'
plt.title(title, fontsize=24)
x = np.arange(1,20)
y = x
plt.plot(x, y)
plt.xlabel('ground truth', fontsize=14)
plt.ylabel('infer result', fontsize=14)
plt.scatter(groud_truths, infer_results,color='green',label='training cost')
plt.grid()
plt.show()
draw_infer_result(groud_truths,infer_results)九:使用k-means算法实现鸢尾花聚类
对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇,让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大
1.利用包完成
鸢尾花数据集描述
包含3种类型数据集,共150条数据 ;2、包含4项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
导入相关包
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets 直接从sklearn.datasets中加载数据集
# 直接从sklearn中获取数据集
iris = datasets.load_iris()
X = iris.data[:, :4] # 表示我们取特征空间中的4个维度
print(X.shape)绘制二维数据分布图
# 取前两个维度(萼片长度、萼片宽度),绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show() 实例化K-means,定义训练函数
def Model(n_clusters):
estimator = KMeans(n_clusters=n_clusters)# 构造聚类器
return estimator
def train(estimator):
estimator.fit(X) # 聚类
# 初始化实例,并开启训练拟合
estimator=Model(3)
train(estimator) 可视化展示
label_pred = estimator.labels_ # 获取聚类标签
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show() 手写完成
# 法一:直接手写实现
# 欧氏距离计算
def distEclud(x,y):
return np.sqrt(np.sum((x-y)**2)) # 计算欧氏距离
# 为给定数据集构建一个包含K个随机质心centroids的集合
def randCent(dataSet,k):
m,n = dataSet.shape #m=150,n=4
centroids = np.zeros((k,n)) #4*4
for i in range(k): # 执行四次
index = int(np.random.uniform(0,m)) # 产生0到150的随机数(在数据集中随机挑一个向量做为质心的初值)
centroids[i,:] = dataSet[index,:] #把对应行的四个维度传给质心的集合
return centroids
# k均值聚类算法
def KMeans(dataSet,k):
m = np.shape(dataSet)[0] #行数150
# 第一列存每个样本属于哪一簇(四个簇)
# 第二列存每个样本的到簇的中心点的误差
clusterAssment = np.mat(np.zeros((m,2)))# .mat()创建150*2的矩阵
clusterChange = True
# 1.初始化质心centroids
centroids = randCent(dataSet,k)#4*4
while clusterChange:
# 样本所属簇不再更新时停止迭代
clusterChange = False
# 遍历所有的样本(行数150)
for i in range(m):
minDist = 100000.0
minIndex = -1
# 遍历所有的质心
#2.找出最近的质心
for j in range(k):
# 计算该样本到4个质心的欧式距离,找到距离最近的那个质心minIndex
distance = distEclud(centroids[j,:],dataSet[i,:])
if distance < minDist:
minDist = distance
minIndex = j
# 3.更新该行样本所属的簇
if clusterAssment[i,0] != minIndex:
clusterChange = True
clusterAssment[i,:] = minIndex,minDist**2
#4.更新质心
for j in range(k):
# np.nonzero(x)返回值不为零的元素的下标,它的返回值是一个长度为x.ndim(x的轴数)的元组
# 元组的每个元素都是一个整数数组,其值为非零元素的下标在对应轴上的值。
# 矩阵名.A 代表将 矩阵转化为array数组类型
# 这里取矩阵clusterAssment所有行的第一列,转为一个array数组,与j(簇类标签值)比较,返回true or false
# 通过np.nonzero产生一个array,其中是对应簇类所有的点的下标值(x个)
# 再用这些下标值求出dataSet数据集中的对应行,保存为pointsInCluster(x*4)
pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 获取对应簇类所有的点(x*4)
centroids[j,:] = np.mean(pointsInCluster,axis=0) # 求均值,产生新的质心
# axis=0,那么输出是1行4列,求的是pointsInCluster每一列的平均值,即axis是几,那就表明哪一维度被压缩成1
print("cluster complete")
return centroids,clusterAssment
def draw(data,center,assment):
length=len(center)
fig=plt.figure
data1=data[np.nonzero(assment[:,0].A == 0)[0]]
data2=data[np.nonzero(assment[:,0].A == 1)[0]]
data3=data[np.nonzero(assment[:,0].A == 2)[0]]
# 选取前两个维度绘制原始数据的散点图
plt.scatter(data1[:,0],data1[:,1],c="red",marker='o',label='label0')
plt.scatter(data2[:,0],data2[:,1],c="green", marker='*', label='label1')
plt.scatter(data3[:,0],data3[:,1],c="blue", marker='+', label='label2')
# 绘制簇的质心点
for i in range(length):
plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=\
(center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='yellow'))
# plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=\
# (center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='red'))
plt.show()
# 选取后两个维度绘制原始数据的散点图
plt.scatter(data1[:,2],data1[:,3],c="red",marker='o',label='label0')
plt.scatter(data2[:,2],data2[:,3],c="green", marker='*', label='label1')
plt.scatter(data3[:,2],data3[:,3],c="blue", marker='+', label='label2')
# 绘制簇的质心点
for i in range(length):
plt.annotate('center',xy=(center[i,2],center[i,3]),xytext=\
(center[i,2]+1,center[i,3]+1),arrowprops=dict(facecolor='yellow'))
plt.show()
dataSet = X
k = 3
centroids,clusterAssment = KMeans(dataSet,k)
draw(dataSet,centroids,clusterAssment)十:基于逻辑回归模型实现手写数字识别
sklearn是Python的一个机器学习的库,它有比较完整的监督学习与非监督学习的模型。本文将使用sklearn库里的分类模型来对手写数字(MNIST)做分类实践。
1.数据介绍
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
2.数据读取与存储形式
将下载好的数据解压带代码目录下即可。 此处直接挂在数据集,数据文件时二进制格式的,所以要按字节读取。代码如下:
!unzip data/data7869/mnist.zip #解压文件
!gzip -dfq mnist/train-labels-idx1-ubyte.gz
!gzip -dfq mnist/t10k-labels-idx1-ubyte.gz
!gzip -dfq mnist/train-images-idx3-ubyte.gz
!gzip -dfq mnist/t10k-images-idx3-ubyte.gzimport struct,os #struct 模块用于处理二进制数据的解析和打包,而 os 模块提供了与操作系统交互的功能。
import numpy as np #array 函数用于创建和操作基本的数组对象。
from array import array as pyarray
from numpy import append, array, int8, uint8, zeros #append 函数用于在数组末尾添加元素,array 函数用于创建数组对象,int8 和 uint8 是整数类型,分别表示有符号和无符号的 8 位整数,zeros 函数用于创建一个全零的数组。
import matplotlib.pyplot as plt
%matplotlib inline #这个魔术命令(magic command)是 Jupyter Notebook 或 JupyterLab 的特殊命令,用于在 Notebook 中内联显示 matplotlib 绘图,并在代码块执行后自动显示图形。def load_mnist(image_file, label_file, path="data/mnist"):
digits=np.arange(10)
fname_image = os.path.join(path, image_file)
fname_label = os.path.join(path, label_file)
flbl = open(fname_label, 'rb')
magic_nr, size = struct.unpack(">II", flbl.read(8))
lbl = pyarray("b", flbl.read())
flbl.close()
fimg = open(fname_image, 'rb')
magic_nr, size, rows, cols = struct.unpack(">IIII", fimg.read(16))
img = pyarray("B", fimg.read())
fimg.close()
ind = [ k for k in range(size) if lbl[k] in digits ]
N = len(ind)
images = zeros((N, rows*cols), dtype=uint8)
labels = zeros((N, 1), dtype=int8)
for i in range(len(ind)):
images[i] = array(img[ ind[i]*rows*cols : (ind[i]+1)*rows*cols ]).reshape((1, rows*cols))
labels[i] = lbl[ind[i]]
return images, labels
train_image, train_label = load_mnist("train-images-idx3-ubyte", "train-labels-idx1-ubyte")
test_image, test_label = load_mnist("t10k-images-idx3-ubyte", "t10k-labels-idx1-ubyte")3.数据展示
image和label都是数组,image内的每个元素为一个784维的向量,label内的每个元素为image同下标下元素表示的数字。
可以将读取到的灰度图通过matplotlib.pyplot展示出来:
import matplotlib.pyplot as plt
def show_image(imgdata,imgtarget,show_column, show_row):
#注意这里的show_column*show_row==len(imgdata)
for index,(im,it) in enumerate(list(zip(imgdata,imgtarget))):
xx = im.reshape(28,28)
plt.subplots_adjust(left=1, bottom=None, right=3, top=2, wspace=None, hspace=None)
plt.subplot(show_row, show_column, index+1)
plt.axis('off')
plt.imshow(xx , cmap='gray',interpolation='nearest')
plt.title('label:%i' % it)
# 显示训练集前50数字
show_image(train_image[:50], train_label[:50], 10,5)
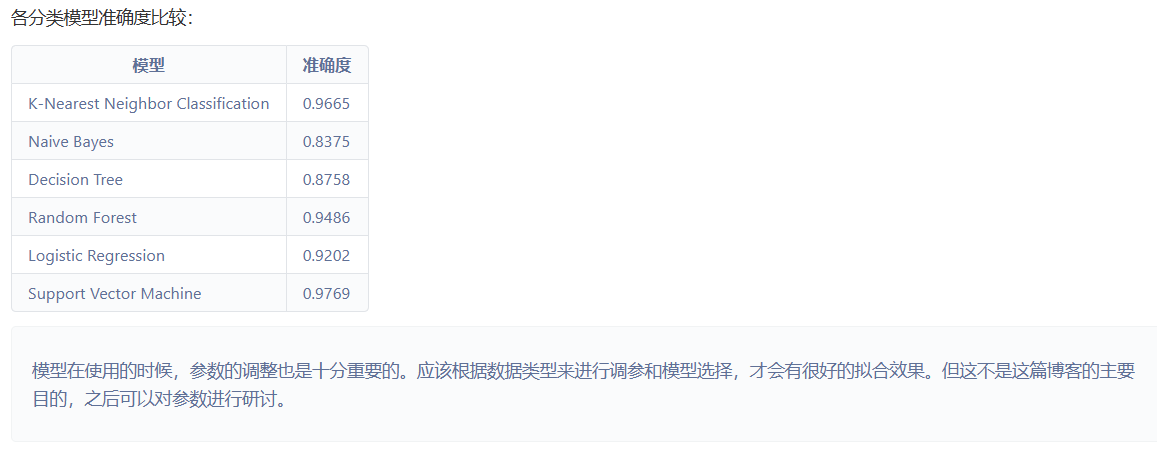
4.sklearn分类模型
本文使用的sklearn分类模型有:
- K-Nearest Neighbor Classification
- Naive Bayes
- Decision Tree
- Random Forest
- Logistic Regression
- Support Vector Machine
5.数据归一化
此处采用min-max标准化将数据进行归一化操作。 image = [im/255.0 for im in image]
K-Nearest Neighbor Classification
from sklearn.metrics import accuracy_score,classification_report
from sklearn.neighbors import KNeighborsClassifier
knc = KNeighborsClassifier(n_neighbors=10)
knc.fit(train_image,train_label.ravel())
predict = knc.predict(test_image)
print("accuracy_score: %.4lf" % accuracy_score(predict,test_label))
print("Classification report for classifier %s:\n%s\n" % (knc, classification_report(test_label, predict)))Naive Bayes
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
mnb.fit(train_image,train_label)
predict = mnb.predict(test_image)
print("accuracy_score: %.4lf" % accuracy_score(predict,test_label))
print("Classification report for classifier %s:\n%s\n" % (mnb, classification_report(test_label, predict)))
Decision Tree
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(train_image,train_label)
predict = dtc.predict(test_image)
print("accuracy_score: %.4lf" % accuracy_score(predict,test_label))
print("Classification report for classifier %s:\n%s\n" % (dtc, classification_report(test_label, predict)))Random Forest
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(train_image,train_label)
predict = rfc.predict(test_image)
print("accuracy_score: %.4lf" % accuracy_score(predict,test_label))
print("Classification report for classifier %s:\n%s\n" % (rfc, classification_report(test_label, predict)))Logistic Regression
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_image,train_label)
predict = lr.predict(test_image)
print("accuracy_score: %.4lf" % accuracy_score(predict,test_label))
print("Classification report for classifier %s:\n%s\n" % (lr, classification_report(test_label, predict)))Support Vector Machine
from sklearn.svm import SVC
svc = SVC()
svc.fit(train_image,train_label)
predict = svc.predict(test_image)
print("accuracy_score: %.4lf" % accuracy_score(predict,test_label))
print("Classification report for classifier %s:\n%s\n" % (svc, classification_report(test_label, predict)))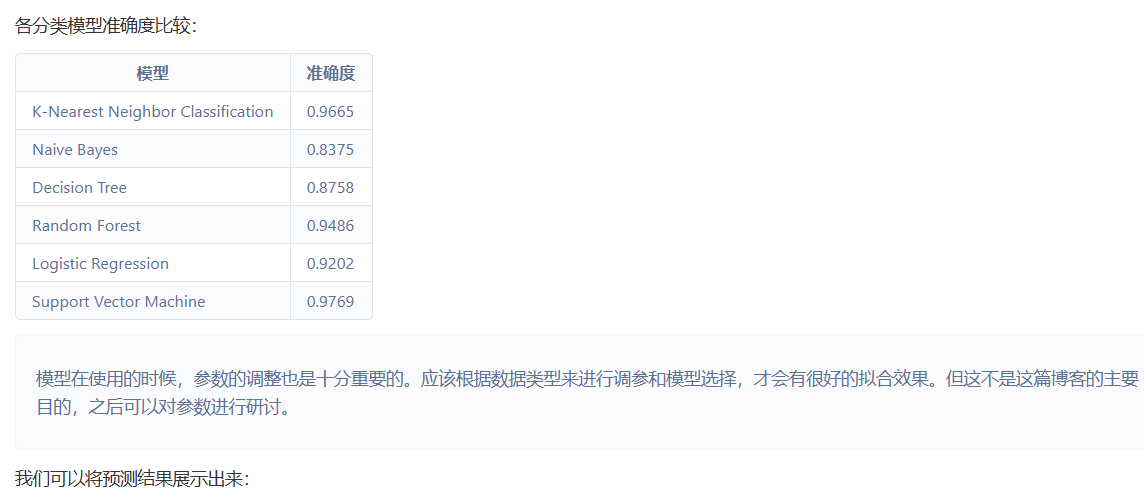
十一:基于朴素贝叶斯实现文本分类

# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory. This directory will be recovered automatically after resetting environment.
!ls /home/aistudio/data
飞桨AI Studio星河社区-人工智能学习与实训社区 (baidu.com)基本上和jack cui的内容一致,贝叶斯分类器,加上拉普拉斯平滑



