54、Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读_哔哩哔哩_bilibili B站才是我的大学,🙁

Diffusion model是一种新的最先进的生成模型,可以生成多样化的高分辨率图像。在OpenAI、Nvidia和Google成功训练大型模型后,它们已经引起了很多关注。基于扩散模型的示例架构包括GLIDE、DALLE-2、Imagen和完整的开源stable diffusion。
Outline
1.Introduction(Denoising Diffusion Model)
Diffusion Models是生成模型,意味着它们用于生成与它们训练的数据类似的数据。从根本上讲,Diffusion Models通过连续添加Gaussian noise来破坏训练数据,然后学习通过反转这个加noising的过程来恢复数据。训练后,我们可以通过将随机抽样的noise通过学习得到的denoising过程来生成数据。

GAN和VAE是两种重要的生成模型,在多个应用中都取得了很大的成功和认可。GAN表现出色,但是由于多种挑战(例如mode collapse和vanishing gradients等),其输出缺乏多样性,且很难训练。VAE有最稳固的理论基础,但是在VAE中建模良好的损失函数是一个挑战,这使得它们的输出是次优的。
Diffusion Modeling的关键概念在于,如果我们能够建立一个学习模型,能够学习由于噪声而导致的信息系统性衰减,那么就应该能够反转这个过程,从噪声中恢复信息。这个概念与VAE相似,它尝试通过首先将数据投影到潜在空间,然后将其恢复到初始状态来优化目标函数。然而,系统的目标不是学习数据分布,而是在Markov链中建模一系列噪声分布,并通过分层方式来解码数据,从而撤消/消除数据中的噪声。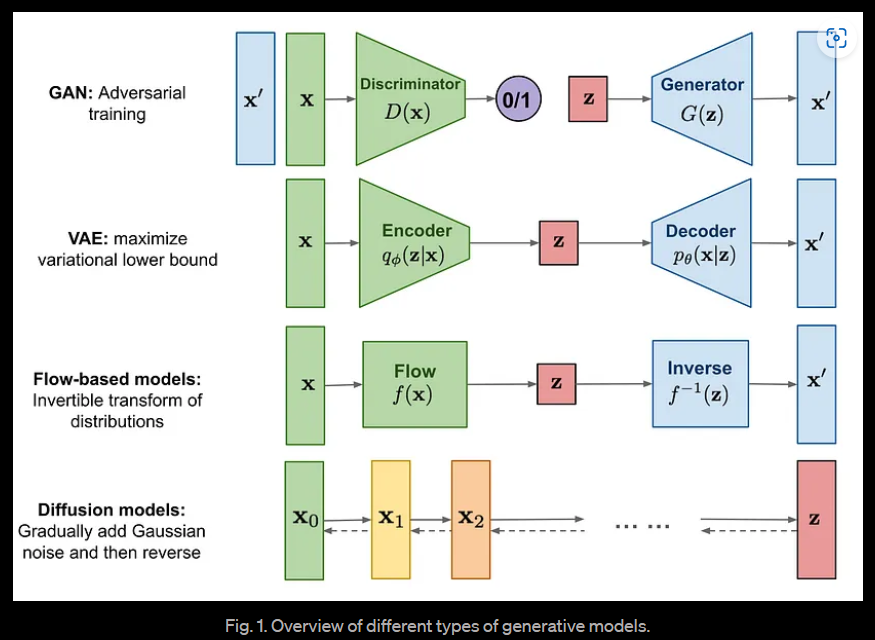
Diffusion model可以被看作是latent variable model。latent variable意味着我们是指一个隐藏的连续特征空间。这样,它们可能看起来类似于variational autoencoders (VAEs)。
有几种基于扩散的生成模型提出了类似的想法,包括diffusion probabilistic models(Sohl-Dickstein et al.,2015年),noise-conditioned score network(NCSN; Yang&Ermon,2019年)和denoising diffusion probabilistic models(DDPM; Ho等人,2020年)。
在实践中,Diffusion model使用了T步的Markov链来建模。这里,Markov链意味着每一步只依赖于前一步,这是一个温和的假设。重要的是,与 flow-based models不同,我们不受限于使用特定类型的神经网络。
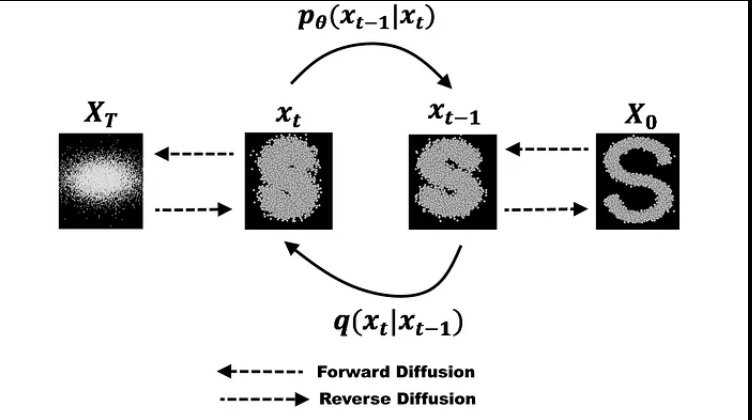
更具体地说,Diffusion Model是一种潜在变量模型,使用固定的Markov链将数据映射到潜在空间。该链逐渐添加噪声到数据中,以获得近似后验q(x1:T | x0)分布,其中x1,….XT是具有相同维度的潜在变量。在下面的图中,我们看到了用于图像数据的这样的Markov链的表现。
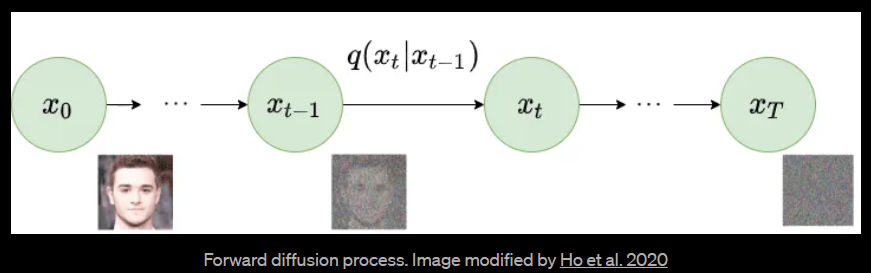
2.Forward diffusion process
更具体地说,DIffusion Model是一种潜在变量模型,使用固定的马尔科夫链将数据映射到潜在空间。改链逐渐添加噪声到数据中,以获得近似后验q(x1:T | x0)分布,其中x1,….XT是具有相同维度的潜在变量。 在下面的图中,我们看到了用于图像数据的这样的 Markov 链的表现。
我们可以正式定义前向扩散过程为一个马尔科夫链,因此,不像VAE中的编码器,它不需要训练。从初始数据点x0开始,我们在接下来的T步中添加方差为 βt 的高斯噪声到 xt-1中,并获得一组具有分布 q(xt | xt-1) 的噪声样本xt。 在时间 t 的概率密度预测仅取决于时间 t-1 的直接前置物,因此可以计算出条件概率密度,如下所示:
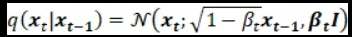
随着步长变大,数据样本x0逐渐失去其可区分的特征。最终当T趋向正无穷的时候,xt等价于一个各向同性的高斯分布。

由于我们处于多维场景中,I是身份矩阵,表示每个维度具有相同的标准差β_t。 请注意,q(xt | xt-1)仍然是一个正态分布,由均值μ和方差Σ定义,其中μt = sqrt(1-βt)* xt-1并且Σt = βtI。 Σ始终是一个具有方差的对角矩阵(这里是βt)。
因此,我们可以以可处理的方式从输入数据 x0 走向封闭形式的 xT。 在数学上,这是后验概率,整个过程的完整分布可以按以下方式计算:
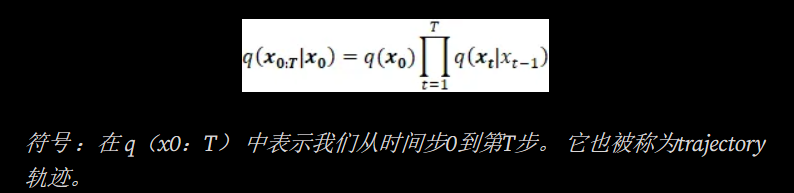
在这里,机率密度函数的平均值和方差取决于参数 βτ,这是一个超参数,其值可以在整个过程中作为常数,也可以在连续的步骤中逐渐改变。 对于微分参数值分配,可以使用一系列函数来模拟行为(例如 sigmoid、tanh、线性等)。
以上的推导足以预测连续的状态,然而,如果我们想在任何给定的时间间隔 t 内进行抽样,而不必经过所有的中介步骤,因此允许一个有效的实现,那么我们可以通过替换超参数为 ατ = 1-βτ 来重新构思上述方程,上述的改组如下:

为了在时间步骤 t 上产生样本,我们可以使用来自热力学的另一个概念 — — 「Langevin dynamics」。 根据随机梯度 Langevin dynamics [2],我们只能通过在马可夫链更新中密度函数的梯度来采样系统的新状态。 基于时间 t-1 上的上一个点,使用步长 ε,可以计算出在时间 t 上的新数据点的采样方式如下:
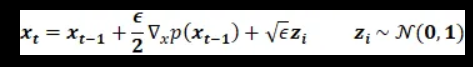
3.Reverse diffusion process
当T趋近于无限大时,latent变量xt几乎是一个各向同性高斯分布。 因此,如果我们能够学习到反向分布 q(xt-1 | xt),就可以从均值为0、协方差矩阵为单位矩阵的正态分布中采样 xt,运行反向过程,获得从 q(x0) 中采样的一个样本,生成一个新的数据点从原始数据分布中。
如果我们可以反转上述过程并从 q(xt-1 | xt) 采样,我们将能够从高斯噪声输入 xT~N(0,I) 中重新创建真实样本。 请注意,如果 βt 足够小,也会是高斯分布。 不幸的是,我们无法轻易地估计 q(xt-1 | xt),因为它需要使用整个数据集,因此我们需要学习一个模型 pθ,以近似这些条件概率,以便运行反向扩散过程。
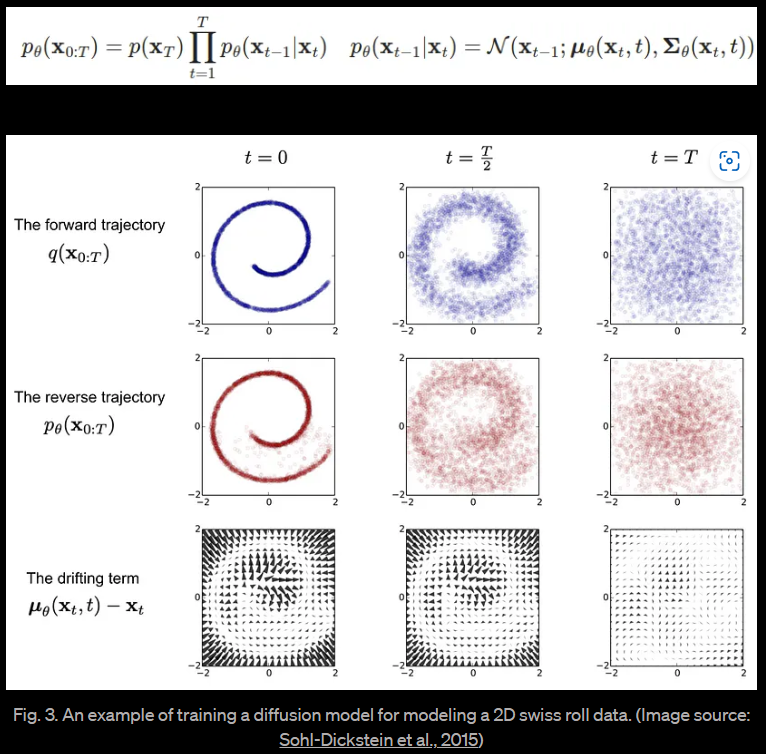
最终,图像渐进地转换为纯高斯噪声。训练扩散模型的目标是学习反向过程——即训练 pθ(xt-1 | xt)。通过沿着这个链向后遍历,我们可以生成新的数据。
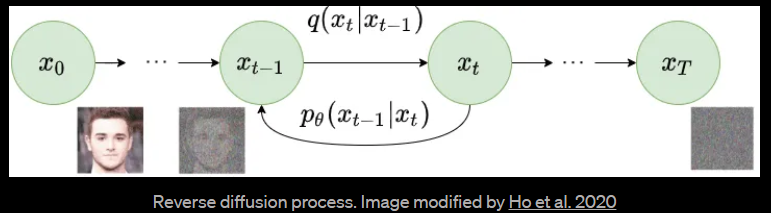
逆向过程需要在当前系统状态的基础上估计当前时间步长的概率密度,这意味着在 t=T 时估计 q(xt-1 | xt) ,并从同质性高斯噪声中生成数据样本。 然而,与正向过程不同的是,从当前状态估计先前状态需要知道所有先前的梯度,而我们无法在没有能够预测此类估计的学习模型的情况下获取它们。 因此,我们必须训练一个神经网络模型,该模型根据学习的权重 θ 和时间 t 的当前状态来估计 ρθ(χτ-1|χτ)。 这可以通过以下方式对所有时间步骤应用反向公式(pθ(x0:T),也称为轨迹,进行估计:

透过将模型加上时间步骤 t 的条件,模型将会学习预测每个时间步骤的高斯参数,而均值函数的参数化是由Ho. et al. [3] 提出的,可以按以下方式计算:

4.Architecture
虽然我们简化过的损失函数旨在训练模型 εθ,但我们仍未定义该模型的架构。 而该模型的唯一要求是其输入和输出的维度相同。
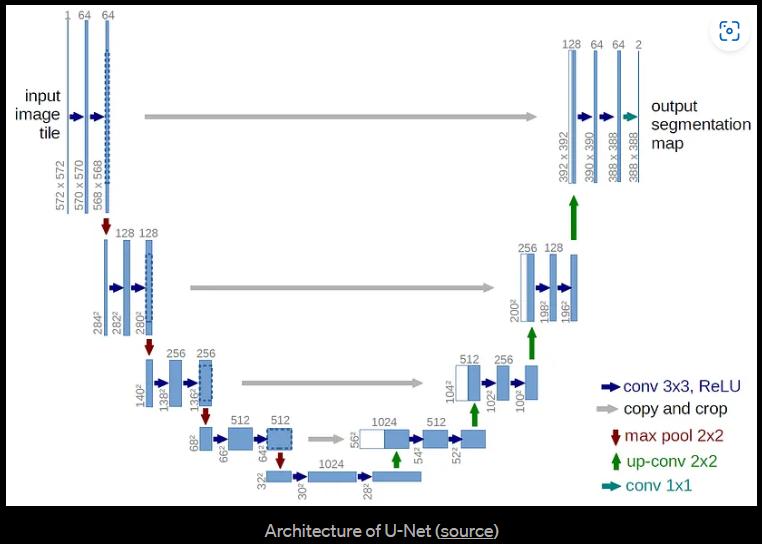
考虑到这一限制,图像Diffusion Model通常使用类似于U-Net的架构实现。
U-Net 是一个对称的架构,其输入和输出具有相同的空间大小,并使用相应特征维度的编码器和解码器块之间的跳过连接。 通常,输入图像首先进行下采样,然后进行上采样,直到达到其初始大小。
在 DDPM 的原始实现中,U-Net 由 Wide ResNet blocks、 group normalization以及 self-attention块组成。
通过在每个残差块中添加正弦position embedding,来指定扩散时间步长 t。
Reverse Process Decoder and L0
在反向过程中,路径包含许多在连续条件高斯分布下的转换。 在反向过程结束时,我们试图生成由整数像素值组成的图像。 因此,我们必须设计一种方法,以获取所有像素的每个可能像素值的discrete (log)概率。
这是通过将反向扩散链中的最后一个转换设置为独立离散解码器来完成的。 为了确定给定图像 x1 的情况下图像 x0 的概率,我们首先将数据维度之间的独立性约束:
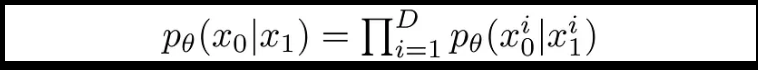
在这里,D 表示数据的维度,上标 i 表示提取一个坐标。 现在的目标是确定对于给定像素,每个整数值的可能性是多少,给定时间 t=1 时稍微有噪声的图像中对应像素的可能值分布:
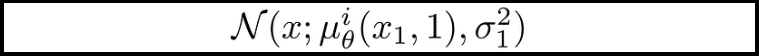
在此,t=1 的像素分布是从下面的多元高斯分布中推导出来的,其对角协方差矩阵允许我们将分布分成单变量高斯分布的乘积,每个数据维度对应一个单变量高斯分布:
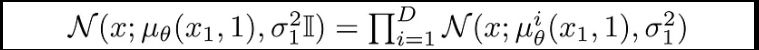
我们假设图像由介于 0、1、…、255 的整数组成(与标准 RGB 图像相同),并已线性缩放至 [-1,1]。 然后,我们将实数线分成小的“桶”,对于给定的缩放像素值 x,该范围的桶是 *[x-1/255, x+1/255]*。 给定 x1 中对应像素的单变量高斯分布,像素值 x 的概率是在以 x 为中心的桶中该单变量高斯分布下的面积。
下面显示了每个桶的面积及其对于平均值为零的高斯分布的概率。 在这种情况下,平均像素值为255/2(半亮度)。 红色曲线表示 t=1 图像中特定像素的分布,而区域则给出了 t=0 图像中相应像素值的概率。

对于每个像素的初始值 t=0,其 pθ(x0|x1) 的值就是它们的乘积。 这个过程可以用以下方程序简洁地表达:

5.Training and sampling algorithms
5.1 Construction of the Model
在扩散模型的训练中使用的模型遵循与VAE网络类似的模式,但与其他网络架构相比,它通常更简单和直接。 输入层的输入大小与数据维度相同。 根据网络要求的深度,可以有多个隐藏层。 中间层是具有相应激活函数的线性层。 最后一层的大小再次与原始输入层的大小相同,因此可以重构原始数据。 在Denoising Diffusion Networks中,最后一层由两个独立的输出组成,分别专门用于预测probability density的mean和variance。
5.2 Computation of Loss Function
网络模型的目标是优化以下损失函数:
Diffusion Model是通过找到最大化训练数据概率的反向Markov转换来进行训练。 实际上,训练相当于最小化负对数似然的变分上限。
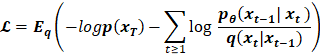
Sohl-Dickstein et al. [1] 提出了这个损失函数的简化形式,它将损失定义为两个高斯分布之间 KL 散度的线性组合和一组熵的形式。 这简化了计算,并使实现损失函数变得容易。 损失函数如下:
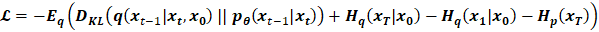
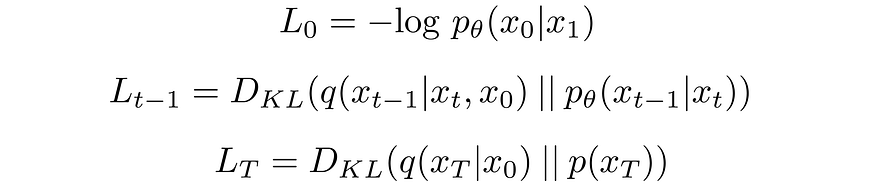
5.3 Kullback-Leibler (KL) Divergences
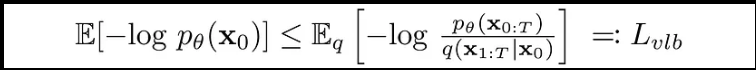
我们希望将Lvlb重写为Kullback-Leibler(KL)散度的形式。 KL散度是一种非对称统计距离度量,用于衡量一个概率分布P与参考分布Q相差多少。 我们有兴趣以KL散度的形式表达Lvlb,因为我们Markov链中的转换分布是高斯分布,而高斯分布之间的KL散度具有封闭形式。
连续分布的 KL 散度的数学形式是
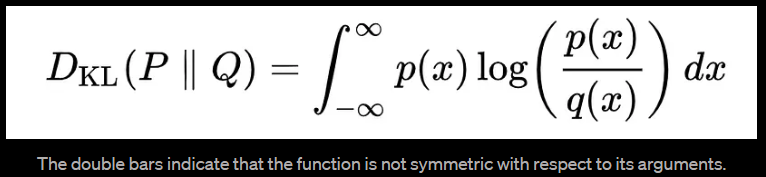
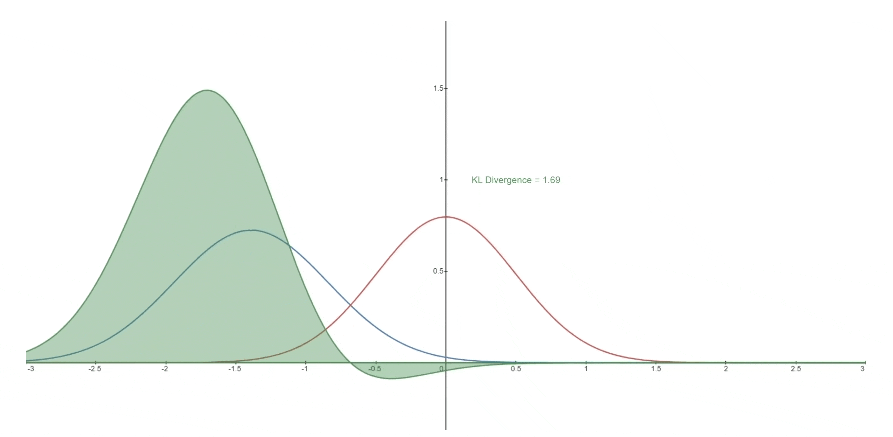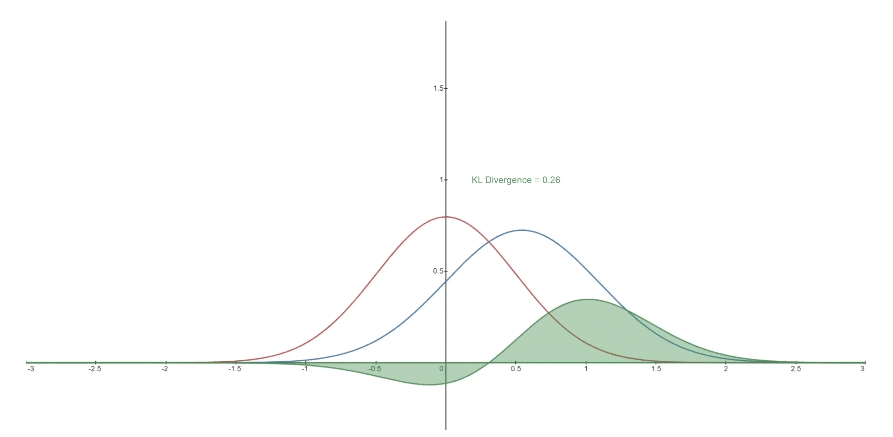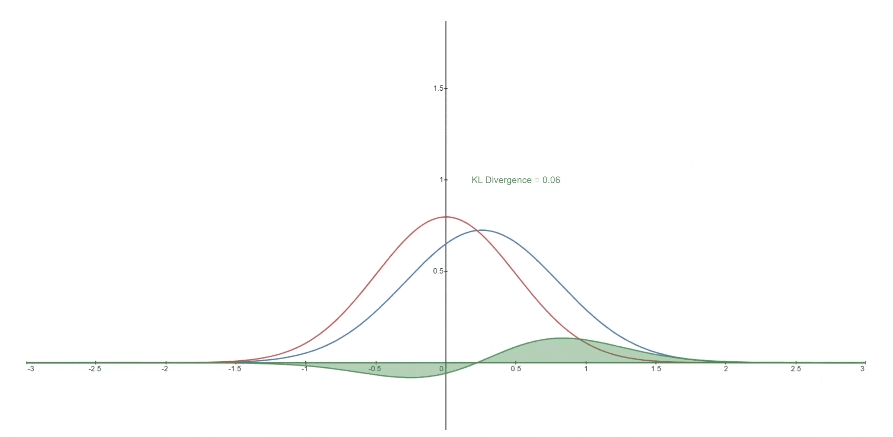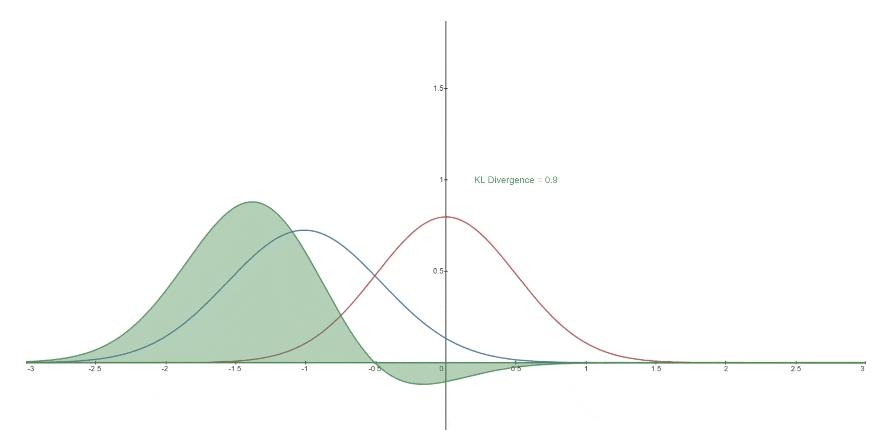
下面您可以看到一个变化的分布* P (蓝色)从参考分布 Q (红色)的KL散度。 绿色曲线表示上面KL散度定义中的积分函数,曲线下总面积表示任何给定时刻P从Q*的KL散度值,这个值也以数字形式显示。
根据 KL 散度投射 Lvlb
在LVLB中,除了L0以外的每个KL项都比较两个高斯分布,因此它们可以以“闭合形式”计算。 LT是常数,可以在训练期间被忽略,因为q没有可学习的参数,而xT是Gaussian noise。 Ho等人(2020年)使用从N(x0; μθ(x1,1),Σθ(x1,1))衍生的单独离散解码器模拟L0。
让我们分别标记变分下限损失中的每个部分:

将Lt-1中的前向过程后验条件于x0,可以得到一个可行的形式,这导致所有KL散度都是高斯之间的比较。 这意味着,可以使用闭式表达式而不是蒙特卡罗估计来精确计算散度。
4.4 Final Objective and Simplification Loss
实验上,Ho et al. (2020) 作者发现在给定时间步长的情况下***预测图像的噪声部分可以产生最佳结果**,并且使用忽略权重项的简化目标执行扩散模型的训练效果更好。 在损失函数中,Ho等人*进一步提出了改进,其中均值的参数化使用了前向过程中上一节所述的方式。
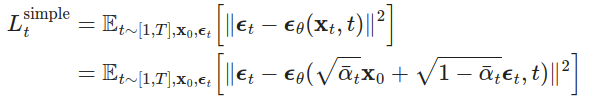
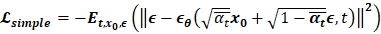
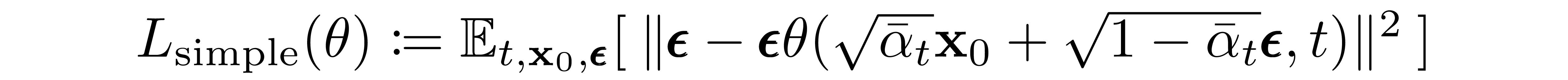
最终的简单目标如下:
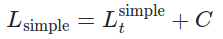
其中,C是不依赖于θ的常数。
Diffusion Model 的训练和抽样算法可以简洁地呈现在下图中:

Fig. 4. The training and sampling algorithms in DDPM (Image source: Ho et al. 2020)

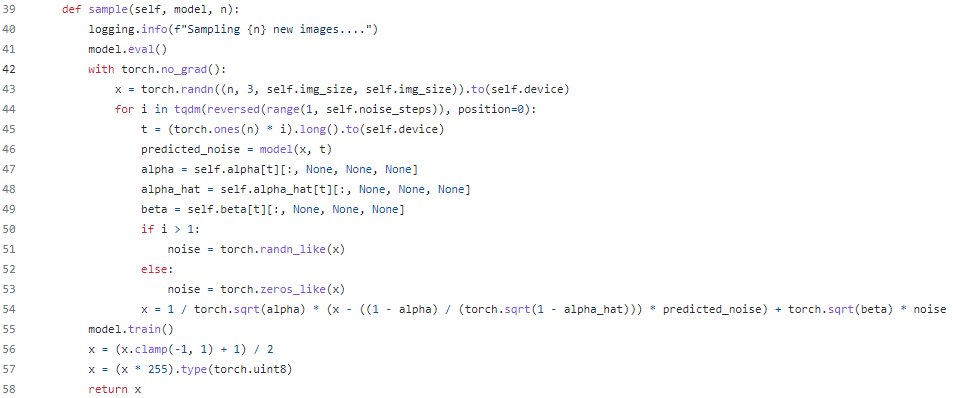
https://github.com/dome272/Diffusion-Models-pytorch
6.Conditioned Generation
扩散模型是有条件的模型,它依赖于先验知识。 在图像生成任务中,prior数据通常是文本、图像或语义地图。 为了获取此条件的潜在表示,使用transformer(例如CLIP)将文本/图像嵌入潜在向量“τ”中。 因此,最终的损失函数不仅取决于原始图像的latent space,也取决于条件的latent embedding, 而这样子以条件化采样过程操纵generated sample,这在这里也称为guided diffusion。
在数学上,引导是指将先验数据分布p(x)与条件y(即类别标签或图像/文本嵌入)进行条件化,从而得到p(x|y)。
要将扩散模型pθ转换为条件扩散模型,可以在每个扩散步骤中添加条件信息y。
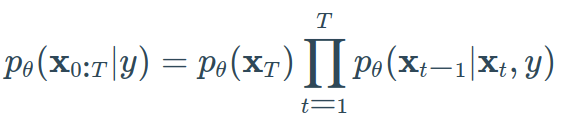
每个时间步骤都看到条件可能是从文本提示获得优秀样本的良好理由。
通常,引导扩散模型旨在学习 ∇log*pθ*(x*t*∣*y*)。 因此,使用贝叶斯规则,我们可以写成:
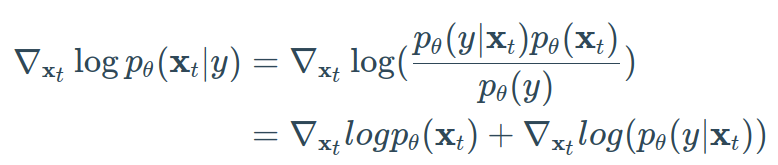
因为梯度运算符∇xt只涉及xt,所以没有y的梯度。 此外,请记住log(ab) = log(a) + log(b)。
透过添加guidance scalar项s,我们得到:
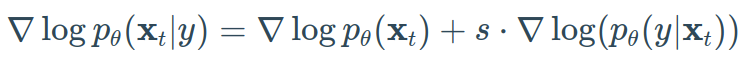
使用这种公式,让我们区分classifier和classifier-free的引导。 接下来,我们将介绍两种旨在injecting label信息的方法种类。
6.1 Classifier guidance
Sohl-Dickstein et al 和后来的Dhariwal and Nichol 显示我们可以使用分类器fφ(y∣xt,t)来指导扩散过程在训练中朝着目标类y方向移动。 为了实现这一点,我们可以使用分类器fφ(y∣xt , t )对噪音图像xt进行训练,以预测其类别y。 然后,我们可以使用梯度∇log(fφ(y∣xt))来指导扩散过程。 具体来说,我们可以建立一个类条件扩散模型,其均值为μθ(xt∣y),方差为Σθ(xt∣y)。
由于pθ ~ N(μθ, Σθ),我们可以使用先前章节的guidance formulation来显示,均值受到类y的logfφ(y∣xt)的梯度干扰,从而产生:
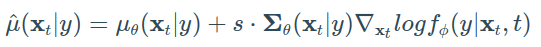
在著名的GLIDE论文中,Nichol等人进一步扩展了这个想法,并使用CLIP嵌入来引导扩散。 CLIP 是由 Saharia 等人提出的,包括一个图像编码器 g 和一个文本编码器 h。 它分别产生图像和文本嵌入 g(xt) 和 h(c),其中 c 是文本标题。
因此,我们可以使用它们的点积来干扰梯度:
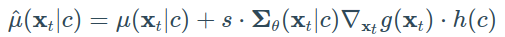
因此,他们成功地将generation process“引导”向user-defined的文本标题。

Algorithm of classifier guided diffusion sampling. Source: Dhariwal & Nichol 2021
6.2 Classifier-Free Guidance
使用与之前相同的公式,我们可以定义一个classifier-free引导扩散模型:
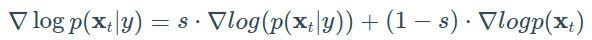
Ho&Salimans提出了不需要第二个分类器模型即可实现引导的方法。 作者们没有训练单独的分类器,而是训练了一个有条件的扩散模型 εθ(xt|y) 和一个无条件的模型 εθ(xt|0)。 实际上,他们使用完全相同的神经网络。 在训练过程中,他们随机将类别 y 设置为 0,以便模型暴露于有条件和无条件的设置:
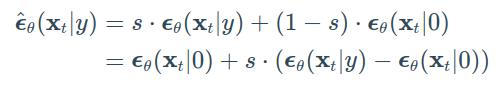
注意,这也可以用于“inject”文本嵌入,就像在classifier guidance中展示的那样。
这个过程虽然有些“奇怪”,但有两个主要优点:
- 它只使用单一模型来引导diffusion。
- 当在条件上需要使用分类器难以预测的信息(例如text embedding)时,它简化了guidance的过程。
7.Stable diffusion: Latent diffusion model
潜变散射模型(Latent diffusion model,LDM; Rombach et al.)基于一个相对简单的思路:不直接在高维输入上应用扩散过程,而是将输入投影到较小的潜变空间中进行扩散运算。
更详细地说,Rombach et al. 提出使用编码器网络将输入编码成潜变表示,即 zt = g(xt)。 这个决策的直觉是通过在较低维空间中处理输入来降低训练扩散模型的计算要求。 之后,应用标准的扩散模型(U-Net)生成新数据,由解码器网络进行上采样。
从逆向扩散过程的马尔可夫链中生成样本的速度非常慢,因为T可能高达一千或几千步。 一个来自Song et al. 2020 的数据点:“例如,从DDPM抽取32x32大小的50k图像需要大约20小时,但使用Nvidia 2080 Ti GPU从GAN中进行抽样需要不到一分钟。 ”
一种简单的方法是运行一个分步抽样计划(Nichol&Dhariwal,2021),每⌈T / S⌉步采取抽样更新,以将过程从T减少到S步。 生成的新抽样计划为{τ1,…,τS},其中τ1 <τ2 <⋯<τS∈[1,T]且S <T。
如果将典型扩散模型(DM)的损失公式化为:
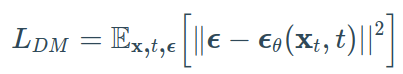
另一种方法是,根据nice property将q_σ(xt−1|xt,x0)改写为以所需标准差σt为参数化的形式。
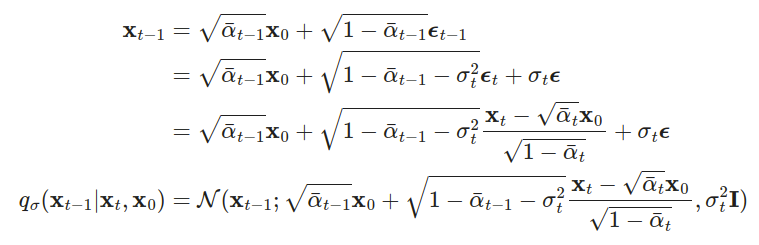
回想一下,在q(xt−1|xt,x0)=N(xt−1; μ
(xt,x0),βtI),因此我们有:
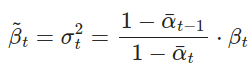
让 σt² = η ·βt~,这样我们就可以调整 η∈ R+ 作为超参数以控制抽样的随机性。 当η=0时,抽样过程变成了 deterministic。 这样的模型称为 denoising diffusion implicit model(DDIM; Song et al., 2020)。 DDIM 具有相同的边际噪声分布,但是可以将噪声映射回原始数据样本。
在生成过程中,我们只对S个扩散步骤{τ1,…,τS}进行抽样,推理过程变为:
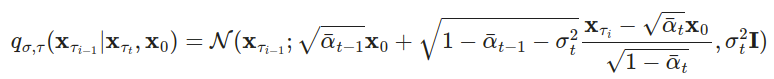
在实验中,所有模型都是用T = 1000个扩散步骤进行训练的,他们观察到当S很小时,DDIM(η = 0)可以产生最好的质量样本,而小S时DDPM(η = 1)表现更差。 当我们有足够的资源运行完整的反向马尔可夫扩散步骤(S = T = 1000)时,DDPM的表现更好。 使用DDIM,可以训练扩散模型达到任意数量的正向步骤,但只能从生成过程的某些步骤中进行抽样。
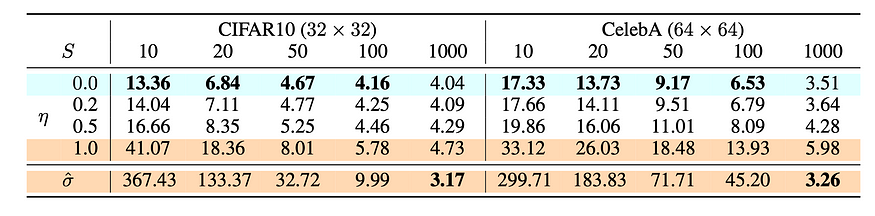
图7. 不同设置下扩散模型的CIFAR10和CelebA数据集上的FID得分,包括DDIM (η=0)和DDPM (σ^)。 (Image source:Song et al.,2020)
相较于DDPM,DDIM能够:
在使用少得多的步骤时生成更高质量的样本。
具有“一致性”特性,因为生成过程是确定性的,这意味着在相同潜变量的条件下产生的多个样本应具有类似的高级特征。
由于具有一致性,DDIM可以在潜在变量中进行语义上有意义的插值。
潜变散射模型 (LDM; Rombach&Blattmann等人,2022) 在潜在空间中运行扩散过程,而不是像素空间,使训练成本更低,推论速度更快。 它的动机来自于观察到图像的大部分位贡献于知觉细节,并且在进行激烈压缩后,语义和概念组成仍然存在。 LDM通过首先使用自编码器削减pixel-level redundancy,然后通过学习到的潜变量在扩散过程上操作/生成语义概念,松散地分解了知觉压缩和语义压缩的生成建模学习。
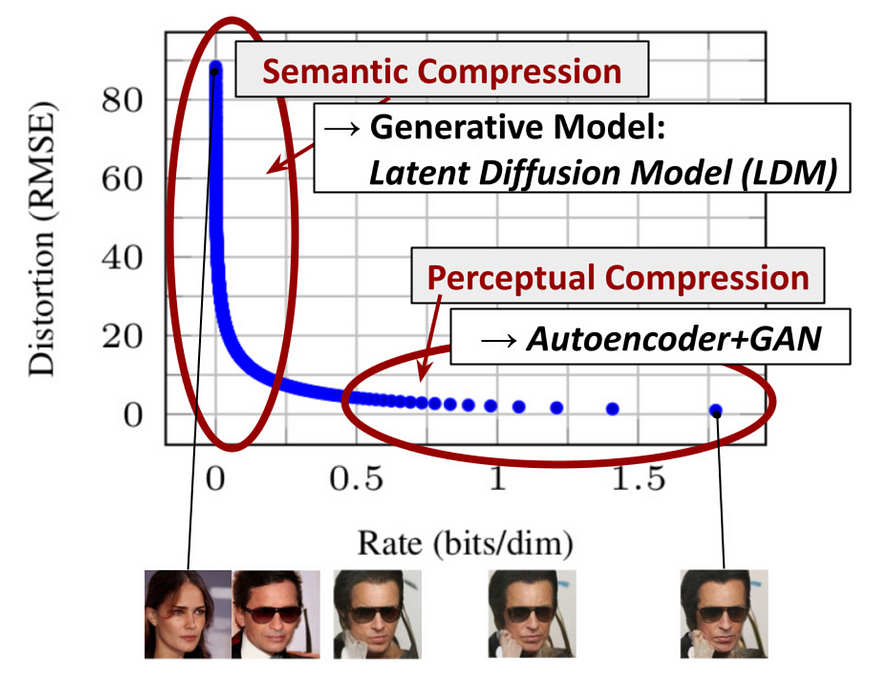
Fig. 8. The plot for tradeoff between compression rate and distortion, illustrating two-stage compressions — perceptural and semantic comparession. (Image source: Rombach & Blattmann, et al. 2022)
知觉压缩过程依赖于自编码器模型。 使用编码器 ε 压缩输入图像 x∈ R HxWx³ 到更小的 2D 潜变量 z=ε(x)R h x w x c,其中下采样率 f=H/h=W/w=2m,m∈N。 然后,解码器 D 从潜变量重建图像,即 x~=D(z)。 本文探讨了自编码器训练中的两种正则化方法,以避免潜变量空间中任意高变异性。
KL-reg: 对学习的潜变量施加小的KL惩罚,以使其接近标准正态分布,类似于VAE。
VQ-reg: 在解码器中使用矢量量化层,类似于 VQVAE,但量化层被解码器吸收。
扩散和去噪过程发生在潜变量 z 上。 去噪模型是一个时间条件下的 U-Net,通过交叉关注机制进行扩展,以处理图像生成的灵活调节信息(例如类别标签、语义地图、图像的模糊变体)。 该设计相当于使用交叉关注机制将不同模态的表示融合到模型中。 每种调节信息都与特定领域的编码器 τθ 配对,以将调节输入 y 投影到可以映射到交叉关注组件的中间表示,τθ(y)∈RM×dτ:
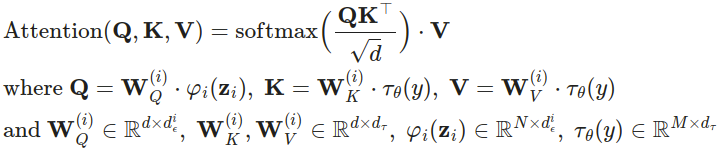
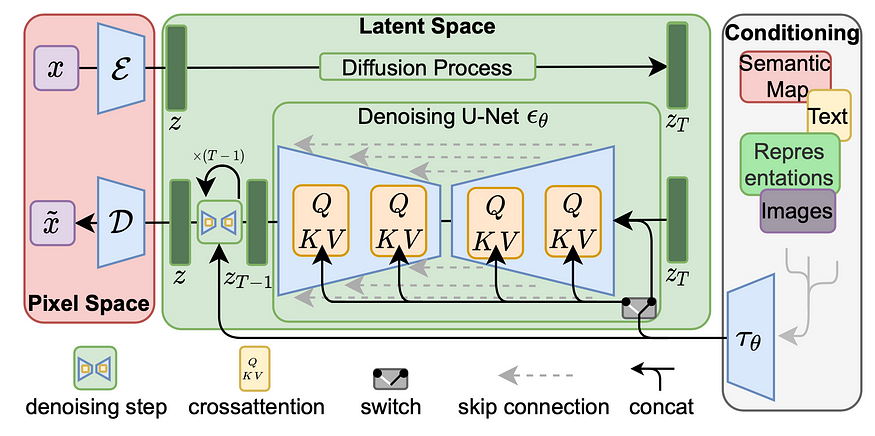
Fig. 9. The architecture of latent diffusion model. (Image source: Rombach & Blattmann, et al. 2022)
8.Summary
在本节中,我们对扩散模型的理论进行了详细的探讨。 从鸟瞰的角度来看,以下是本节中最重要的几点:
- 我们的扩散模型被参数化为Markov chain,这意味着我们的潜在变量x1,…,xT仅取决于前一个(或后一个)时间步。
- 马尔可夫链中的transition distributions是高斯分布,其中前向过程需要一个方差计划,而反向过程的参数是学习的。
- 扩散过程确保了当T足够大时,xT渐近地分布为一个各向同性的高斯分布。
- 在我们的情况下,方差计划是固定的,但也可以进行学习。 对于固定的计划,按照几何进度可能比按线性进度获得更好的结果。 无论哪种情况,方差通常随着时间在系列中增加(即i<j时βi<βj)。
- 扩散模型非常灵活,允许使用任何输入和输出维度相同的架构。 许多实现使用类似于U-Net的架构。
- 训练目标是最大化训练数据的可能性。 这表现为调整模型参数以最小化数据的负对数概率的变分上限。
- 由于我们的马尔可夫假设,几乎所有目标函数中的项都可以被表示为KL散度。 由于我们使用的是高斯分布,因此这些值易于计算,因此无需进行蒙特卡罗近似。
- 最终,使用简化的训练目标来训练预测给定潜在变量的噪声组件的函数会产生最好且最稳定的结果。
- 在反向扩散过程的最后一步中,使用离散解码器获取像素值的log likelihoods。



