

json.dumps()函数
`json.dumps()`是Python标准库中的一个函数,用于将Python对象序列化为JSON格式的字符串。该函数接受一个Python对象作为输入,返回一个JSON格式的字符串。以下是该函数的基本语法:
```
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False)
```
其中,`obj`参数是要序列化为JSON格式的Python对象。其他参数均为可选参数,具体含义如下:
- `skipkeys`:如果为True,则在序列化过程中跳过字典中键不是字符串的项,默认为False。
- `ensure_ascii`:如果为True,则将所有非ASCII字符转义为Unicode转义序列,默认为True。
- `check_circular`:如果为True,则在序列化过程中检查循环引用,默认为True。
- `allow_nan`:如果为True,则允许序列化NaN、Infinity或-Infinity,默认为True。
- `cls`:用于自定义JSON编码器的类,默认为None。
- `indent`:用于指定缩进级别的空格数,默认为None。
- `separators`:用于指定JSON格式字符串中各个元素之间的分隔符,默认为(`,`, `:`)。
- `default`:用于指定自定义对象的序列化函数,默认为None。
- `sort_keys`:如果为True,则在序列化过程中按照键的字母顺序对字典进行排序,默认为False。
`json.dumps()`函数使用时需要注意以下几点:
1. 输入的Python对象必须是可序列化的。可序列化的Python对象包括列表、元组、字典、数字、字符串和布尔值等基本数据类型,以及这些基本数据类型的嵌套组合。
2. JSON格式的字符串中,键必须是字符串类型,而且必须使用双引号进行包围。
3. 如果需要将JSON格式的字符串转换为Python对象,则可以使用`json.loads()`函数。
以下是一个使用`json.dumps()`函数将Python对象序列化为JSON格式的字符串的示例:
```
import json
data = {'name': 'Alice', 'age': 20, 'gender': 'female'}
json_str = json.dumps(data)
print(json_str)
```
在这个示例中,我们将一个字典对象`data`序列化为JSON格式的字符串,然后将结果打印输出。输出结果如下:
```
{"name": "Alice", "age": 20, "gender": "female"}
```
可以看到,`json.dumps()`函数将字典对象`data`序列化为了一个JSON格式的字符串。在这个JSON格式的字符串中,键都被转换为了字符串类型,并且使用双引号进行包围。json.loads函数
`json.loads()`是Python标准库中的一个函数,用于将JSON格式的字符串反序列化为Python对象。该函数接受一个JSON格式的字符串作为输入,返回一个Python对象。以下是该函数的基本语法:
```
json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None,
parse_constant=None, object_pairs_hook=None, **kw)
```
其中,`s`参数是要反序列化为Python对象的JSON格式的字符串。其他参数均为可选参数,具体含义如下:
- `cls`:用于自定义JSON解码器的类,默认为None。
- `object_hook`:用于自定义JSON解码器中对象的反序列化函数,默认为None。
- `parse_float`:用于自定义JSON解码器中浮点数的反序列化函数,默认为None。
- `parse_int`:用于自定义JSON解码器中整数的反序列化函数,默认为None。
- `parse_constant`:用于自定义JSON解码器中常量(如NaN、Infinity等)的反序列化函数,默认为None。
- `object_pairs_hook`:用于自定义JSON解码器中字典的反序列化函数,默认为None。
- `kw`:用于传递其他参数的关键字参数。
`json.loads()`函数使用时需要注意以下几点:
1. 输入的JSON格式字符串必须符合JSON规范。
2. 在JSON格式字符串中,键必须是字符串类型,而且必须使用双引号进行包围。
3. `json.loads()`函数返回的Python对象类型取决于JSON格式字符串的内容。例如,如果JSON格式字符串表示一个字典,`json.loads()`函数将返回一个Python字典对象;如果JSON格式字符串表示一个列表,`json.loads()`函数将返回一个Python列表对象。
以下是一个使用`json.loads()`函数将JSON格式字符串反序列化为Python对象的示例:
```
import json
json_str = '{"name": "Alice", "age": 20, "gender": "female"}'
data = json.loads(json_str)
print(data)
```
在这个示例中,我们将一个JSON格式的字符串`json_str`反序列化为Python对象`data`,然后将结果打印输出。输出结果如下:
```
{'name': 'Alice', 'age': 20, 'gender': 'female'}
```
可以看到,`json.loads()`函数将JSON格式的字符串`json_str`反序列化为了一个Python字典对象`data`。在这个字典对象中,键都被转换为了字符串类型,并且没有双引号包围。dump和dumps,load和loads
在Python中,`json`模块提供了一组用于处理JSON格式数据的函数和类。其中,`dumps`、`dump`、`loads`、`load`是最常用的四个函数,它们的主要区别如下:
- `json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False)`:将Python对象序列化为JSON格式的字符串,返回一个字符串。`dumps`函数的输出结果是一个字符串,可以直接写入文件或通过网络传输。
- `json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False)`:将Python对象序列化为JSON格式的字符串,并将其写入文件对象中。`dump`函数的输出结果是将JSON格式的字符串写入文件对象中,而不是返回一个字符串。
- `json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)`:将JSON格式的字符串反序列化为Python对象,返回一个对象。`loads`函数的输入是一个JSON格式的字符串,输出是一个Python对象。
- `json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)`:从文件对象中读取JSON格式的字符串,并将其反序列化为Python对象。`load`函数的输入是一个文件对象,输出是一个Python对象。
总的来说,`dumps`和`dump`两个函数的区别在于输出的结果不同,`loads`和`load`两个函数的区别在于输入的数据来源不同。在使用这些函数的时候需要注意输入参数和输出结果的类型及其格式要求。机器学习分类算法实践
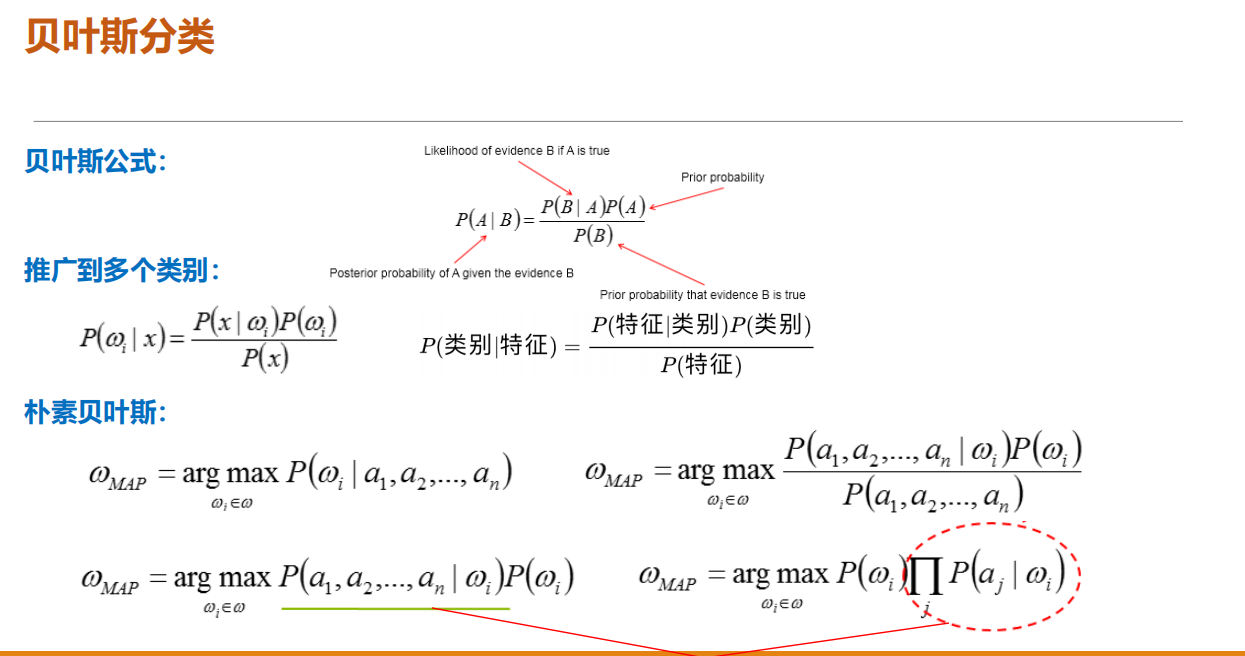
核心算法:决策树,贝叶斯,SVM,逻辑回归

sum函数
这段代码定义了一个`sum`函数,它是一个方法(在类中定义的函数),可以通过类的实例进行调用。让我们解释一下这个函数以及它的参数。
```python
def sum(self, axis=None, dtype=None, out=None, keepdims=False, initial=0, where=True):
```
这个函数用于计算数组元素沿指定轴(axis)的和。下面是对各个参数的解释:
- `axis`: 指定进行求和操作的轴。默认为`None`,表示对整个数组进行求和。如果指定了一个整数值,表示沿着该轴进行求和。例如,`axis=0`表示按列求和,`axis=1`表示按行求和。
- `dtype`: 指定返回结果的数据类型。默认为`None`,表示保持原始数组的数据类型。可以指定其他数据类型,如`int`、`float`等。
- `out`: 指定用于存储结果的输出数组。默认为`None`,表示创建一个新的数组来存储结果。
- `keepdims`: 指定是否保持结果数组的维度。默认为`False`,表示结果数组的维度会被压缩,即去掉长度为1的维度。如果设为`True`,则结果数组会保持和原数组相同的维度。
- `initial`: 指定一个初始值,用于在求和之前累加到结果中。默认为0,表示不使用初始值。
- `where`: 指定一个条件数组,用于选择参与求和的元素。默认为`True`,表示所有元素都参与求和。条件数组的形状必须与原数组相同。
这个函数的具体实现没有提供,因为是从文档字符串(docstring)中恢复的签名信息。函数的实际实现可能在其他地方定义。
这个函数与NumPy库中的`numpy.sum`函数具有相同的功能,可以参考`numpy.sum`函数的文档来了解更多细节。
要使用这个函数,需要通过类的实例来调用,例如`array_instance.sum()`,其中`array_instance`是一个数组对象的实例。np.tile()函数
`np.tile`函数是NumPy库中的一个函数,用于将数组沿指定的轴重复。
函数的语法如下:
```python
np.tile(arr, reps)
```
其中,`arr`是要重复的数组,`reps`是一个表示重复次数的元组。
`np.tile`函数将数组 `arr` 沿指定的轴重复 `reps` 次,生成一个新的数组。重复的方式是将数组按照指定的次数堆叠在一起。
下面是一些示例来详细介绍 `np.tile` 函数的使用:
**示例 1:重复一维数组**
```python
import numpy as np
a = np.array([1, 2, 3])
b = np.tile(a, 3)
print(b)
```
输出结果:
```
[1 2 3 1 2 3 1 2 3]
```
在这个例子中,一维数组 `[1, 2, 3]` 被重复了 3 次,生成了一个新的一维数组 `[1, 2, 3, 1, 2, 3, 1, 2, 3]`。
**示例 2:重复二维数组**
```python
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.tile(a, (2, 3))
print(b)
```
输出结果:
```
[[1 2 1 2 1 2]
[3 4 3 4 3 4]
[1 2 1 2 1 2]
[3 4 3 4 3 4]]
```
在这个例子中,二维数组 `[[1, 2], [3, 4]]` 被沿着行和列分别重复了 2 次和 3 次,生成了一个新的二维数组。
**示例 3:重复多维数组**
```python
import numpy as np
a = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
b = np.tile(a, (2, 1, 2))
print(b)
```
输出结果:
```
[[[1 2 1 2]
[3 4 3 4]]
[[5 6 5 6]
[7 8 7 8]]
[[1 2 1 2]
[3 4 3 4]]
[[5 6 5 6]
[7 8 7 8]]]
```
在这个例子中,三维数组 `[[[1, 2], [3, 4]], [[5, 6], [7, 8]]]` 被沿着第一个轴重复了 2 次,沿着第三个轴重复了 2 次,生成了一个新的三维数组。
`np.tile` 函数可以用于在数组中进行重复操作,扩展数组的维度和大小。这对于构建一些特定形状的数组或者进行数组的扩展和填充非常有用。aixs=0表示行之间,既是按照列排序;aixs=1表示按照列之间,既是按照行进行排序
argsort()函数
`argsort()` 是 NumPy 库中的一个函数,用于返回数组排序后的索引值。它返回的索引值表示排序后的元素在原数组中的位置。
函数的语法如下:
```python
np.argsort(arr, axis=-1, kind=None, order=None)
```
参数说明:
- `arr`: 要排序的数组。
- `axis`(可选): 沿着指定的轴进行排序,默认为最后一个轴。
- `kind`(可选): 排序算法的种类。可选值包括`'quicksort'`、`'mergesort'`、`'heapsort'`,或者使用`None`表示使用默认的排序算法。
- `order`(可选): 如果数组是结构化数据类型(如结构化数组),则可以指定要排序的字段。
`argsort()` 函数返回一个与原数组形状相同的数组,其中的元素是原数组中排序后的索引值。
下面是一些示例来说明 `argsort()` 函数的使用:
**示例 1:一维数组排序索引**
```python
import numpy as np
a = np.array([3, 1, 2])
indices = np.argsort(a)
print(indices)
```
输出结果:
```
[1 2 0]
```
在这个例子中,一维数组 `[3, 1, 2]` 被排序后的索引值是 `[1, 2, 0]`。也就是说,索引为 1 的元素是最小的,索引为 2 的元素是第二小的,索引为 0 的元素是最大的。
**示例 2:二维数组按列排序索引**
```python
import numpy as np
a = np.array([[3, 1, 2], [4, 2, 1]])
indices = np.argsort(a, axis=0)
print(indices)
```
输出结果:
```
[[0 0 1]
[1 1 0]]
```
在这个例子中,二维数组 `[[3, 1, 2], [4, 2, 1]]` 按列进行排序后的索引值是 `[[0, 0, 1], [1, 1, 0]]`。也就是说,第一列中索引为 0 的元素最小,索引为 1 的元素次小;第二列中索引为 0 的元素最小,索引为 1 的元素次小;第三列中索引为 1 的元素最小,索引为 0 的元素次小。
`argsort()` 函数对于排序和获取排序索引非常有用,可以方便地进行数组的排序操作,并通过索引值获取排序后的元素。sort()函数
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
这段代码是使用Python的内置函数`sorted`对字典`classCount`按值进行排序的示例。它将字典的键值对按照值从大到小的顺序进行排序,并将结果保存在`sortedClassCount`中。
让我们逐步解释代码中的每个部分:
1. `classCount.items()`: 这部分将字典`classCount`转换为一个包含键值对的元组列表。每个元组由字典中的键和对应的值组成。
1. `key=operator.itemgetter(1)`: 这部分指定了用于排序的关键字。在这里,`operator.itemgetter(1)`表示按照元组的第二个元素(也就是值)进行排序。
1. `reverse=True`: 这部分指定了排序的顺序。当设置为`True`时,元组按照降序排列;当设置为`False`时,元组按照升序排列。在这个例子中,设置为`True`表示按照值从大到小的顺序进行排序。
1. `sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)`: 这是最终的排序操作。`sorted`函数接受一个可迭代对象作为输入,并返回一个新的已排序的列表。在这里,它接受了字典`classCount.items()`作为输入,并根据指定的排序关键字和顺序对元组进行排序。
最后,排序的结果被赋值给变量`sortedClassCount`,它是一个已排序的包含键值对的列表。元素按照值从大到小排列,可以按照需要进一步处理和使用这个列表。
这种使用`sorted`函数的方式对于对字典按值排序是一种常见的方法,它提供了一种简单而有效的方式来获取排序后的结果。collections.Counter(k_labels).most_common(1)
`collections.Counter(k_labels).most_common(1)` 是一个用于统计列表 `k_labels` 中元素出现频率的操作。
这段代码的执行过程如下:
1. `collections.Counter(k_labels)` 创建了一个 `Counter` 对象,该对象用于统计 `k_labels` 列表中每个元素的出现次数。
1. `most_common(1)` 是 `Counter` 对象的方法,它返回出现频率最高的 1 个元素及其计数。返回的结果是一个列表,其中包含一个元组,元组的第一个元素是出现频率最高的元素,第二个元素是该元素的计数。
举个例子,假设 `k_labels` 是一个包含分类标签的列表:
```python
k_labels = ['A', 'B', 'C', 'A', 'A', 'B']
```
使用 `collections.Counter(k_labels).most_common(1)` 将返回出现频率最高的元素及其计数:
```python
[('A', 3)]
```
结果表示在 `k_labels` 列表中,元素 `'A'` 出现了 3 次,而它是出现频率最高的元素。
你可以根据具体的需求进行适当的修改和使用,例如获取出现频率最高的多个元素,或者根据出现频率进行排序等。#针对有BOM的UTF-8文本,应该去掉BOM,否则后面会引发错误。arrayOLines[0]=arrayOLines[0].lstrip(‘\ufeff’)
`arrayOLines[0]=arrayOLines[0].lstrip('\ufeff')` 这行代码的作用是去掉字符串 `arrayOLines[0]` 开头的 BOM(Byte Order Mark)字符。
BOM 是一种特殊的字符,用于标识文本文件的字节顺序和编码方式。在某些 UTF-8 编码的文本文件中,会在文件开头插入一个 BOM 字符,以指示文件是以 UTF-8 编码保存的。
然而,有些程序或库在处理文本时可能不会正确处理 BOM 字符,会将其当作普通字符处理,导致后续的操作出错。为了避免这种问题,可以使用 `lstrip()` 方法去掉字符串开头的 BOM 字符。
具体来说,`lstrip('\ufeff')` 的作用是从字符串的左侧开始移除所有的 `\ufeff` 字符。这里的 `\ufeff` 是 BOM 字符的 Unicode 编码表示。
通过将 `arrayOLines[0]` 的开头的 BOM 字符去除后,可以确保后续的操作不会受到 BOM 字符的干扰,避免因 BOM 导致的错误。
BOM(Byte Order Mark)字符是一种特殊的字符,用于标识文本文件的字节顺序和编码方式。它通常出现在以 Unicode 编码保存的文本文件的开头。
BOM 字符的作用是向读取文件的程序或库提供关于文件编码和字节顺序的信息。它可以帮助程序正确解析和处理文本文件,尤其是当文件使用不同的 Unicode 编码(如 UTF-8、UTF-16)保存时。
在 UTF-8 编码的文本文件中,BOM 字符的表示是 `\ufeff`。它通常以字节序列 `EF BB BF` 的形式出现在文件的开头,用于指示文件是以 UTF-8 编码保存的。
需要注意的是,并非所有的 UTF-8 编码的文本文件都包含 BOM 字符。BOM 字符在 UTF-8 编码中是可选的,而且有些程序或库可能不支持处理 BOM 字符。因此,在处理文本文件时,特别是在不确定是否存在 BOM 字符的情况下,可能需要进行适当的处理,如去除 BOM 字符或进行编码转换。
总结:BOM 字符是用于标识文本文件字节顺序和编码方式的特殊字符,通常出现在以 Unicode 编码保存的文本文件的开头。在 UTF-8 编码的文本文件中,BOM 字符的表示是 `\ufeff`。lstrip()函数
`lstrip()` 是 Python 字符串对象的一个方法,用于从字符串的左侧(开头)删除指定的字符或字符集合。这个方法的名称 "lstrip" 是 "left strip" 的缩写,表示从左侧剥离或删除字符。
语法:
```python
string.lstrip([characters])
```
参数说明:
- `characters`(可选):指定要删除的字符或字符集合,默认为删除字符串开头的空白字符(空格、制表符等)。
`lstrip()` 方法会返回一个新的字符串,其中删除了开头的指定字符或字符集合。原始字符串本身不会被修改。
示例用法:
```python
string = " Hello, World! "
new_string = string.lstrip() # 默认删除开头的空白字符
print(new_string) # 输出:"Hello, World! "
new_string = string.lstrip("H ") # 删除开头的字符 "H" 和空格
print(new_string) # 输出:"ello, World! "
```
在示例中,`lstrip()` 方法分别用于删除字符串开头的空白字符和指定的字符。可以根据具体的需求选择要删除的字符或字符集合,或者省略参数以删除默认的空白字符。returnMat[index,:] = listFromLine[0:3]这个是什么意思
这行代码是将一个列表 (`listFromLine`) 的前三个元素赋值给一个二维数组 (`returnMat`) 的指定行 (`index`)。
假设 `returnMat` 是一个二维 NumPy 数组,具有多行和三列的形状。`index` 是一个整数,表示要赋值的目标行的索引。
代码解析:
`listFromLine[0:3]` 表示从 `listFromLine` 列表中获取索引 0 到索引 2 的元素,即前三个元素。
`returnMat[index, :]` 表示将指定行 (`index`) 的所有列都选中,形成一个切片。
将 `listFromLine` 的前三个元素赋值给 `returnMat` 的指定行,可以通过以下代码实现:
```python
returnMat[index, :] = listFromLine[0:3]
```
这将把 `listFromLine` 的前三个元素分别赋值给 `returnMat` 的指定行的每一列。注意,前提是 `returnMat` 必须具有足够的行数和列数来存储赋值操作的结果。
例如,如果 `index` 是 2,`returnMat` 是一个形状为 (3, 3) 的数组,`listFromLine` 是包含至少三个元素的列表,那么上述代码将把 `listFromLine` 的前三个元素赋值给 `returnMat` 的第三行。plt.step()
`plt.setp()`是Matplotlib中的一个函数,用于设置一个或多个对象的属性。
在你提供的代码中,`axs0_title_text`是一个标题文本对象,它位于`axs[0, 0]`子图中。`plt.setp(axs0_title_text, size=9, weight='bold', color='red')`的作用是设置该标题文本的字体大小为9,字体粗细为粗体(bold),字体颜色为红色。
通过这种方式,你可以使用`plt.setp()`函数对Matplotlib对象的属性进行批量设置,从而快速自定义图形的外观和样式。
请注意,`axs0_title_text`对象需要是可设置属性的对象,例如标题文本对象、坐标轴对象等。如果将`plt.setp()`函数应用于不支持的对象类型,可能会导致错误。为什么我不加数据归一化,错误率能高16%
数据归一化在机器学习中是一种常用的预处理技术,它有助于提高模型的性能和收敛速度。如果你没有对数据进行归一化,可能会导致以下几个问题:
1. 不同特征的尺度不同:如果不同特征的取值范围差异很大,某些特征可能会对模型的学习产生更大的影响,而其他特征的影响则相对较小。这可能导致模型在训练过程中偏向于重要特征,而忽略了其他特征的贡献,从而影响了模型的性能。
1. 算法对尺度敏感:某些机器学习算法对特征的尺度非常敏感,例如欧氏距离计算、支持向量机等。如果特征没有进行归一化,这些算法可能无法正确地衡量特征之间的相似性或权重。通过归一化,可以确保各个特征在相同的尺度上进行比较,避免尺度带来的偏差。
1. 收敛速度慢:在一些优化算法中,例如梯度下降法,特征的尺度差异可能导致收敛速度变慢。如果某些特征的值范围较大,梯度下降算法需要更多的迭代才能达到最优解。通过归一化,可以加快优化算法的收敛速度。
因此,数据归一化可以帮助消除特征之间的尺度差异,提高模型的性能和稳定性。在某些情况下,数据归一化可以显著降低错误率,并帮助模型更好地利用数据特征。cv2.imread()函数介绍
`cv2.imread`是OpenCV库中的一个函数,用于从磁盘上的图像文件中读取图像数据,并将其加载为NumPy数组。
函数的基本语法如下:
```python
cv2.imread(filename, flags)
```
其中,`filename`是要读取的图像文件的路径,可以是绝对路径或相对路径。`flags`是一个可选参数,用于指定图像的读取方式。常用的`flags`取值如下:
- `cv2.IMREAD_COLOR`:默认值,读取彩色图像,忽略图像的透明度(如果有)。
- `cv2.IMREAD_GRAYSCALE`:以灰度模式读取图像。
- `cv2.IMREAD_UNCHANGED`:读取图像,并包括图像的所有通道,包括透明度(如果有)。
`cv2.imread`函数会返回一个包含图像数据的NumPy数组。对于彩色图像,返回的数组的形状为 `(高度, 宽度, 通道数)`,通道数为3,分别表示红色、绿色和蓝色通道。对于灰度图像,返回的数组的形状为 `(高度, 宽度)`,只有一个通道,表示灰度值。
以下是一个示例:
```python
import cv2
# 读取彩色图像
image_color = cv2.imread('image.jpg', cv2.IMREAD_COLOR)
# 读取灰度图像
image_gray = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
```
在使用`cv2.imread`函数时,需要确保指定的图像文件路径是正确的,并且程序对该路径具有读取权限。如果路径错误或文件不存在,函数将返回空值(`None`)。因此,在使用返回值之前,建议进行错误检查。jieba.lcut()
`jieba.lcut()`是`jieba`中文分词库中的一个函数,用于对中文文本进行分词操作。该函数采用了基于统计的分词方法以及一些其他的规则和技巧来实现中文分词。
下面是`jieba.lcut()`函数的分词过程简要描述:
1. 加载内置的词典:`jieba.lcut()`函数在执行之前会先加载内置的中文词典。这些词典包含了常见的词汇和词语,用于基本的分词操作。
1. 构建有向无环图(DAG):根据输入的文本,`jieba.lcut()`函数会根据词典中的词语构建一个有向无环图(DAG)。DAG中的节点表示文本中的字符,边表示可能的词语。
1. 应用动态规划算法:基于构建的DAG,`jieba.lcut()`函数使用动态规划算法来计算最大概率路径,以确定最可能的分词结果。在计算最大概率路径时,考虑了词语的频率、词语长度、上下文信息等因素。
1. 返回分词结果:根据计算得到的最大概率路径,`jieba.lcut()`函数将文本切分成词语,并返回一个包含分词结果的列表。
需要注意的是,`jieba.lcut()`函数默认使用精确模式进行分词,即尽可能多地切分出词语。此外,`jieba`库还提供了其他分词函数,如`jieba.cut()`和`jieba.lcut()`,可以根据需要选择不同的分词模式。
总的来说,`jieba.lcut()`函数通过利用统计算法、动态规划和内置词典等技术,实现了对中文文本的分词操作,将文本切分成有意义的词语,并返回分词结果的列表。


